



ベイズ流のニューラルネットワークの定式化を説明します。
とにかくすごいパンダ本を参考にしてます。



ニューラルネットワークとは
ニューラルネットワークとは、大体の機械学習モデルの元になっているモデルです。以下のような写真で表されることが多いです。

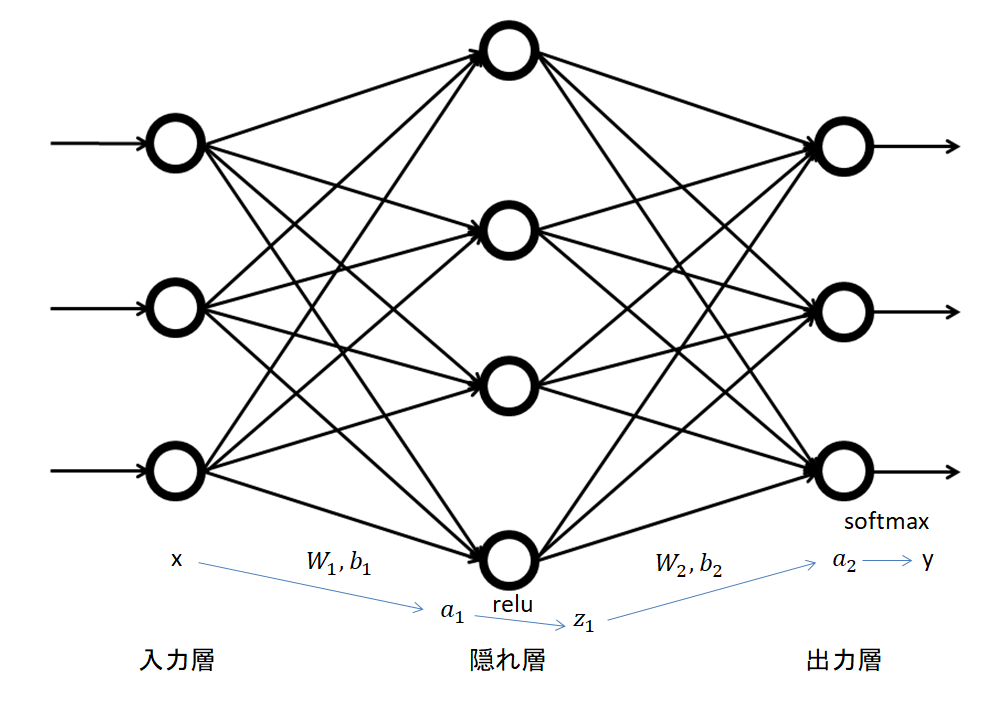
〇印一つ一つをセルと呼び、縦1列の事を層と呼びます。1そして、一番左側の層を入力層、一番右側の層を出力層、それ以外の層は隠れ層と呼ばれます。
ニューラルネットワークでは、セルとデータが対応しているイメージになります。上の図では、3次元のベクトルデータ\( (3,1) \)から3次元の値を予測するモデルになっています。
直線で結ばれているセル同士はパラメーターによる掛け算を行います。大体のモデルでは、全結合を使います。つまり、入力層のセルを\(x \) , 隠れ層のセルを\(a \)で表して、 (入力層のサイズ, 出力層のサイズ) の行列 を\(W \)で表すと
$$\begin{eqnarray}
a=Wx
\end{eqnarray}$$
で表されるような構造を使います。隠れ層は、活性化関数と呼ばれる関数を施して、複雑な現象に対応できるように非線形性を持たせます。多くの場合はrelu 関数やsigmoid関数が使われます。
最後に、出力層ですが、分類問題を解きたい時は活性化関数としてsoftmax関数を考えます。具体的な数値や画像そのものを出力したい時は何も施さずに答えとして出力層の数値を受け取ります。
隠れ層の数や、層毎のセルの数、活性化関数の種類は人間が与えるべきパラメーターです。一方で、行列の成分は学習で与えます。
上の図を数式で表して置きます。回帰の問題を考える事にします。入力層から隠れ層への行列を\(W_1\),隠れ層での活性化関数を\(z\),隠れ層から出力層への行列を\(W_2 \)と置きます。また、行列の成分全てを、\(\mathbb{w} \)で表します。ニューラルネットワークを関数
$$\begin{eqnarray}
f(-;\mathbb{w}):\mathbb{R}^{input} \rightarrow \mathbb{R}^{output}
\end{eqnarray}$$
と見なすと、以下のように書けます。
$$\begin{eqnarray}
f(x;\mathbb{w})=W_2 z(W_1 x)
\end{eqnarray}$$
具体的なパラメーターの学習は、誤差関数Eを定めて、Eを最小化するようにパラメーターを調整します。大体の場合はEのパラメーター\(\mathbb{w} \)での微分を0にするようにします。
具体的に計算するのは大変なので、学習率を人間が与えて勾配法で行ったりします。最も簡単な勾配法は以下のようにパラメーターを更新します。ただし、\(\eta \)で学習率を表します。
$$ \begin{eqnarray}
w_{new}=w + \eta \frac{\partial E}{\partial w}
\end{eqnarray}$$
ベイズニューラルネットワークの定式化
ベイズニューラルネットワークは、予測したい値が従う確率分布を求める手法です。 教師データを\((Y,X )\)で表し、パラメーター全体を\(W\)で表します。2 また、ニューラルネットワークは\(f(-; W )\)で表します。 \(Y ,X,W\)の関係を表す確率分布や、パラメーターの事前分布、\(X,W\)を与えたときの\(Y\)が従う確率分布を仮定し、適切な\( p(W|X,Y )\)からパラメーターをサンプルする事が出来れば、
ベイズニューラルネットワークが完成します。3
ニューラルネットワークは、過学習という問題が起きがちですが、ベイズニューラルネットワークの場合、確率分布を決定して、そこからサンプルして答えを取り出すので過学習という概念がそもそもありません。そこが長所です。
パラメーターなどの確率分布を仮定しましょう。
$$\begin{eqnarray}
p(W)&=& \prod_{w \in W }\mathcal{N}(w|0,\sigma _{w} ^2)\\
p(Y,W|X)&=& p(W)\prod p(y_n|x_n, W_n )\\
p(y_n |x_n , W)&=& \mathcal{N}(y_n |f(x_n;W), \sigma _{y} ^2 I)
\end{eqnarray}$$
ただし、\(\mathcal{N}(x|\mu , \sigma ^2 ) \)で平均\( \mu \), 分散\(\sigma^2 \)の正規分布を表しています。多次元の正規分布も同じ記号で表します。
パラメーターの学習
事後分布\(p(W|X,Y) \)は以下のように求めていきます。
ベイズの定理から、
$$\begin{eqnarray}
p(W|X,Y) \propto p(W) p(Y|X,W)
\end{eqnarray}$$
です。\( p(Y,X,W )\)は正規分布ではありますが、平均値がニューラルネットワークの出力になるので、\(W \)については非線形で複雑な形をしています。そこで、\( p(W|X,Y) \)はラプラス近似します。ラプラス近似は、求めたい確率分布の極大値を与える点から正規分布を作って近似する方法です。
ラプラス近似については解説記事があるので読んでみてください。
https://masamunetogetoge.com/laplace-bayeslogistic
ラプラス近似を行う為に、事後分布の対数尤度を計算します。
$$\begin{eqnarray}
\log p(W|X,Y) &=& \sum \log p(y_n|x_n, W_n ) + \log p(W) +{\rm const }\\
&=& -\sum_{n} \frac{1}{2\sigma _{y ^2}^2 } \| f(x_n;W_n) -y_n \| ^2-\sum_{n}\sum_{w \in W_n}\frac{1}{2\sigma_{w} ^2} w^2 + {\rm const }
\end{eqnarray}$$
これをパラメーター\(w\) で微分すれば、パラメーターの事後分布の推定が出来ます。
$$\begin{eqnarray}
\frac{\partial \log p(W|X,Y)}{\partial w} = -\left( \frac{ \partial E_{NN} }{\partial w} +\frac{w}{\sigma _{w} ^2}\right)
\end{eqnarray}$$
具体的な式を書くと大変なので、ニューラルネットワークの部分は\(E_{NN} \)でまとめました。
これは、ニューラルネットワークで、誤差関数をMSEとした場合と同じなので、既存のコードだったりで計算出来ます。隠れ層1層くらいなら、手で計算してもそんなに大変ではありません。
学習によって決定されたパラメーターたちを\( W_{Map } \)と置き、\( \Lambda (W_{Map} ) \)を事後分布のヘッシアンの\(W_{Map} \)での値とします。
$$\begin{eqnarray}
\Lambda (W_{Map} ) =- \nabla _{W} \otimes \nabla_{W }\log p(W|X,Y ) |_{W_{Map}}
\end{eqnarray}$$
として、事後分布の近似は以下のように置きます。
$$\begin{eqnarray}
p(W|X,Y) \sim q(W) = \mathcal{N}\left( W|W_{MAP} . \Lambda (W_{MAP})^{-1} \right)
\end{eqnarray}$$
事後分布の近似
パラメーターが得られたら、新しいデータを与えたときの予測値の事後分布を考えます。つまり、
$$\begin{eqnarray}
p(y_{\ast} |x_{\ast} X,Y)
\end{eqnarray}$$
を計算します。これは、ラプラス近似で得たパラメーターの事後分布\(q(W) \)を使って、
$$\begin{eqnarray}
p(y_{\ast} |x_{\ast} X,Y) \sim \int p(y_{\ast} |x_{\ast} ,W) q(W) dW
\end{eqnarray}$$
で近似します。左辺の積分は、ニューラルネットを介しての複雑な値なので、そのまま積分するのは大変です。という訳で、ニューラルネットワークを\(W \)に関する一次関数で近似しましょう。4
\(W_{MAP }\)で、ラプラス近似に用いた負の対数尤度を最大化するパラメーターを表し、ニューラルネットワークを\(W \)についての関数と見なして、\( W_{MAP} \)の周りでテーラー展開します。
$$\begin{eqnarray}
f(x_{\ast};W)\sim f(x_{\ast};W_{MAP} ) +\left( \nabla_{W} f(x_{\ast};W ) |_{W_{MAP}} \right) ^T(W-W_{MAP})
\end{eqnarray}$$
ただし、\( \nabla_{W} f(x_{\ast};W ) |_{W_{MAP}} \)は、ニューラルネットワークの出力の成分毎に勾配を取って縦ベクトルを作り、それを出力順に横に並べた行列である事に注意しましょう。
こうすることで、事後分布の平均値が\(W \)について一次関数になるので、計算が出来ます。
$$\begin{eqnarray}
g &=& \nabla_{W} f(x_{\ast};W ) |_{W_{MAP} } \\
\mu _W &=& f(x_{\ast};W_{MAP})+g^T(W-W_{MAP})
\end{eqnarray}$$
と置くことで次のようになります。
$$\begin{eqnarray}
p(y_{\ast} |x_{\ast} X,Y) & \sim &\int p(y_{\ast} |x_{\ast} ,W) q(W) dW \\
&\sim & \int dW \mathcal{N}( y_{\ast}|\mu _W, \sigma_{y} ^2)
\mathcal{N} (W|W_{MAP}, \Lambda (W_{MAP} )^{-1} ) \\
&= & \mathcal{N}\left( y_{\ast} |f(x_{\ast},W_{MAP}), \sigma(x_{\ast} )^2 \right)
\end{eqnarray}$$
ただし、\( \sigma (x_{\ast} )^2 = \sigma _{y}^2 + g^T \Lambda (W_{MAP} ) ^{-1} g\)です。計算は、1次元の正規分布に関する等式の類推から分かります。5
$$\begin{eqnarray}
\mathcal{N}(y|a+b(x-x_0 ) ,\sigma _y ^2 ) \mathcal{N}(x|x_0, \sigma _x ^2 ) = \mathcal{N}(x-x_0 |\mu _x , \tilde{\sigma} ^2 ) \mathcal{N}(y|a, \tilde{\sigma} ^2 )
\end{eqnarray}$$
ただし、
$$\begin{eqnarray}
\tilde{\sigma} ^{-2} &=& \frac{b^2 }{\sigma _y ^2 } + \frac{1}{\sigma _x ^ 2} \\
\mu _x &=& \frac{b \tilde{\sigma} ^{2} }{\sigma _y ^2}(y-a)
\end{eqnarray}$$
この式は左辺の対数を取って式を整理すれば出てきます。事後分布の式では、\(x -x_0 \)に当たる部分6 が積分されて1になるので、最後の結果になります。
結局は、ラプラス近似に使用する\(W_{MAP} \)と微分の値、 ニューラルネットワークのMSEに関するパラメーターでの微分があれば学習から予測まで行う事が出来ます。
まとめ
- ニューラルネットワークの復習をした
- ベイズニューラルネットワークの説明をした
- パラメーターの学習には普通のニューラルネットワークの微分も使う
- 予測にはラプラス近似を使う