


2020年11月現在、web アプリをdjango+pythonで作っています。
その過程でSQLも少し触ったのですが、SQLでデータを大量に集めたは良いものの、上手く使えない事がありそうだなと感じました。
今回の記事では、SQLにデータを集めたという仮定の元、python側にデータを渡して解析するというのをやってみます。
SQLは初心者なので変なことを書く可能性があるので、twitterで教えてください。
SQLとは
SQLとは、関係データベース管理システム (RDBMS) において、データの操作や定義を行うためのデータベース言語(問い合わせ言語)、ドメイン固有言語である。プログラミングにおいてデータベースへのアクセスのために、プログラミング言語と併用されるが、SQLそのものはプログラミング言語ではない。
https://ja.wikipedia.org/wiki/SQL から引用
上にあるように、RDBMSを扱う言語みたいなものの事をSQLと呼びます。
SQLを扱う為のプラットフォーム(?)はいくつかあり、MySQL,PostgreSQL,BIGQUERYなどがあります。
ふわっとした言い方をすると、RDBMSとは、データテーブルをいくつか用意して、特別な列同士に関係を持たせてデータテーブルを繋いだものです。
E-R図
RDBMSを使う時は、E-R図というもので、データベースの全貌を表します。
PostgreSQLで配布されているサンプルのデータセットのE-R図は次のようになっています。

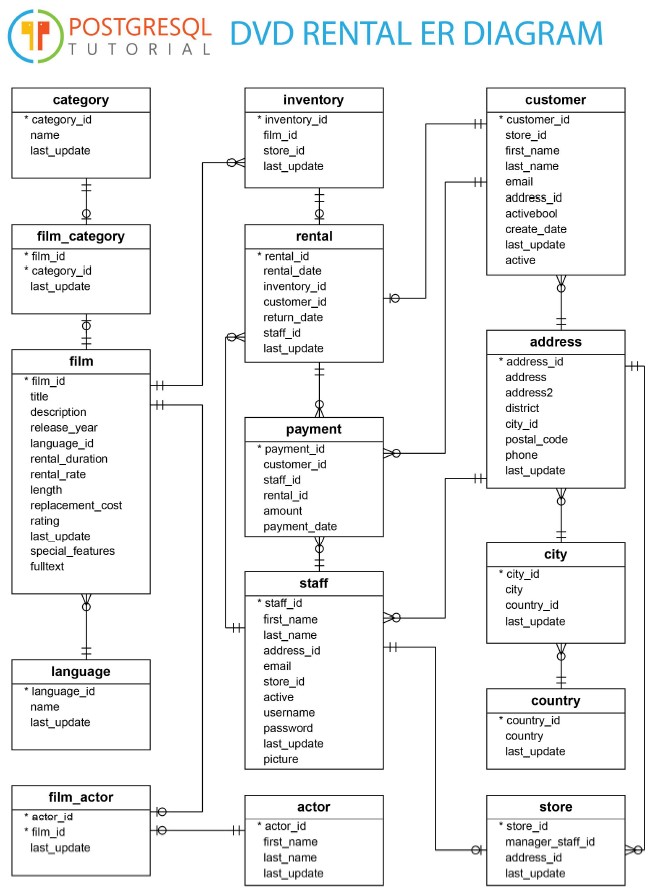
データテーブルの名前と、格納されているデータの列名をまとめて、関係を矢印などで示しています。
詳しい読み方などは、別のサイトを参照してみてください。例えば、以下のサイトに書いています。
https://qiita.com/ramuneru/items/32fbf3032b625f71b69d
SQLからデータを取り出す
この記事の中では、PostgreSQLを使います。また、データベースは上のE-R図で使った、PostgreSQLのチュートリアルのモノを使います。
実際に触ってみたい人は、PostgreSQLをインストールして、チュートリアル用のデータを以下からダウンロードしておいてください。



また、SQLの文法が良く分からない人は、以下の記事を読むとイメージが沸くかもしれません。
https://www.slideshare.net/i_Pride/pandassql

気持ちとしては、データベースのテーブルと列を見て、
SELECT (col1, col2, col3 ... ) FROM 結合されたテーブル WHERE 何か条件とすることで、欲しいデータが得られます。
実際にチュートリアルページからダウンロードしたデータでやってみます。
dvdrental データベースの中身を見る
チュートリアルのデータは、dvdrental という名前のデータベースで、映画の名前や出演俳優、従業員や店の情報がまとめられています。全てを見ると大変なだけなので、categoryとfilmを取り出してみます。
取りあえず、category tableの中身を見ます。

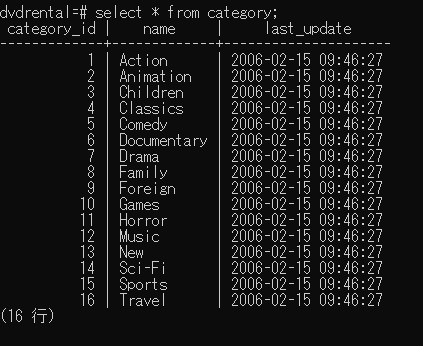
category_id とname,last_update が1対1になっています。1これは、RDBMSの特徴で、
1つのテーブルの中では重複したデータが無い事になっています。
E-R図を見てみると、categoryとfilmはfilm_categoryのfilm_idとcategory_idを通じて繋がっているようです。

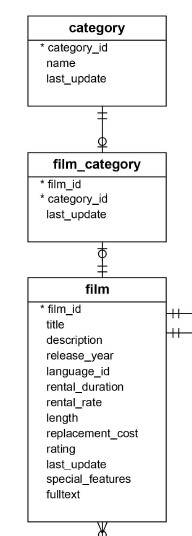
カテゴリー名、映画タイトル、解 をいくつか取得してみましょう。

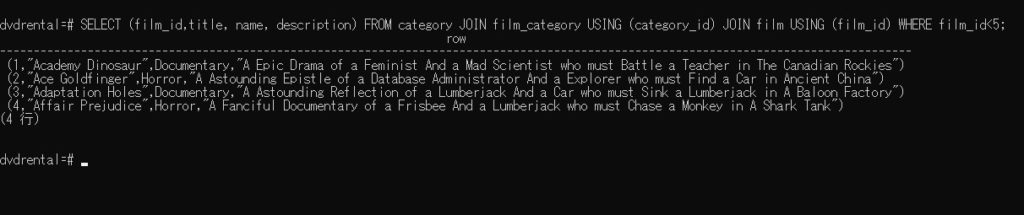
このデータをcsvに出力して、pandasで読み込めば、pythonで色々出来ます。
例えば、映画のタイトルからカテゴリー名を予測する、とかで遊ぶことが出来ます。
CSVに出力する
PostgreSQLでは、テーブルなどをcsvに出力するコマンドが2つ用意されています。
以下のサイトで解説されています。

今回はローカルに出力します。
\COPY ( SELECT film_id,title, name, description FROM category JOIN film_category USING (category_id) JOIN film USING (film_id)) TO 'filepath.csv' WITH CSV DELIMITER HEADER;これでfile_path.csvにcsvファイルが出来ています。
データを解析する
映画のタイトルと解説、ジャンルが格納されたデータを出力したので、少しだけ中身を見ましょう。
取り合えず、生データを少しだけみて、ジャンルの分布がどうなっているか確認します。
data.head()
"""
film_id title name description
0 1 Academy Dinosaur Documentary A Epic Drama of a Feminist And a Mad Scientist...
1 2 Ace Goldfinger Horror A Astounding Epistle of a Database Administrat...
2 3 Adaptation Holes Documentary A Astounding Reflection of a Lumberjack And a ...
3 4 Affair Prejudice Horror A Fanciful Documentary of a Frisbee And a Lumb...
4 5 African Egg Family A Fast-Paced Documentary of a Pastry Chef And ...
"""data.name.value_counts().plot(kind="bar", title ="number of genres")
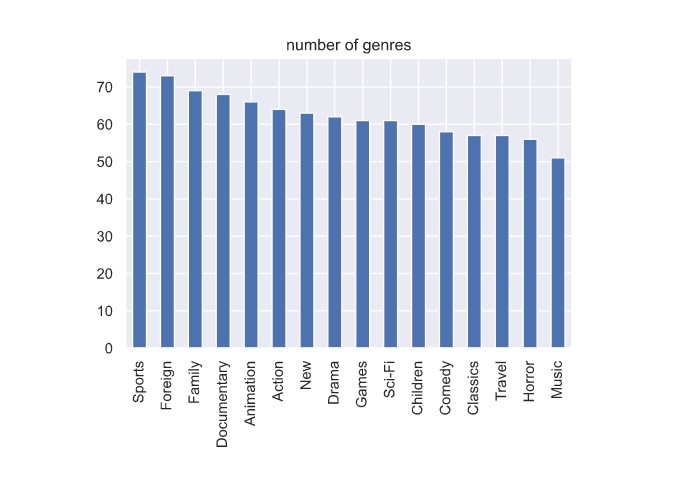
全てのジャンルの映画が、大体同じ数あるみたいです。
実際のデータも、この記事を足掛かりにして、解析できるはずです。
まとめ
- SQLの紹介をした
- SQLのコマンドの紹介をした
- SQLからデータをcsvに出力した
- pythonでデータを読んだ