



実務で有用な統計手法の一つに、分散分析があります。例えば、適切な実験計画に基づいて実験をした時の結果の解析や、日々蓄積しているデータの変化点の分析などに使う事が出来ます。
特に、実験条件によって、得られた結果の平均値は変化しているか?変化点を境にデータの平均値は変化しているか?といった疑問に答える事が出来ます。
最もシンプルな場合について原理を解説し、適当なデータに対して分散分析を行います。
参考文献は一応下記の本です。エクセルで全部出来るという所が良いです。



記事で使っているソースコードはgithub に置いてあります。
https://github.com/msamunetogetoge
変動の分解
制御されるパラメーターが一つの場合に使う分散分析は、一元配置法と呼ばれます。Rなどでは、(One-Way) ANOVAと呼ばれます。
以下のようなデータが取得されていると仮定します。

例えばエクセルでは、1行目に条件名、各行の行方向に取得されたデータが並んでいるイメージです。
データがまとまっている表をそのまま行列と見なすと、データ全体は以下のようにまとめる事が出来ます。
$$\begin{eqnarray}
X=
\begin{pmatrix}
x_{11} &\cdots & x_{1m} \\
x_{21} & \cdots & x_{2m} \\
\vdots & \vdots & \vdots \\
x_{n_1 1} & \cdots & x_{n_m m}
\end{pmatrix}
\end{eqnarray}$$
\(n_i \)で\(i \)列目の条件のデータ数を表しています。必ずしも\(n_1 = \cdots =n_m \)となる必要はありません。全データ数は\(N\)としておきます。
一元配置法では、全データの変動のうち、どの程度が条件の変化によって生じているのかを調べます。つまり、以下のようなテープ図を考えて、条件を変えた事による変動の割合を調べます。


上の図で、条件を変えた事による変動の割合が大きい時、条件を変えるとデータの平均値が変化すると考えるのが一元配置法です。1
具体的に式を見ていきます。
全データの平均を\(\bar{x} \)とすると、全データの変動は以下のように書けます。
$$\begin{eqnarray}
S_T = \sum_{j=1} ^{m} \sum_{i=1}^{n_j} (x_{ij}-\bar{x} )^2
\end{eqnarray}$$
変動は、平均値に関する和の公式などを用いて、以下のように分解する事が出来ます。2
$$\begin{eqnarray}
S_T &=& S_R +S_E \\
S_R &=& \sum_{j=1} ^{m} \sum_{i=1}^{n_j} ( \bar{x_{j}} -\bar{x} )^2 \\
S_E &=& \sum_{j=1} ^{m} \sum_{i=1}^{n_j} ( x_{ij} – \bar{x_{j}} )^2
\end{eqnarray}$$
ただし、\(\bar{x_j} = \sum_{i} x_{ij} /n_j \)はj列目のデータの平均値を表しています。
図にすると以下のようになります。

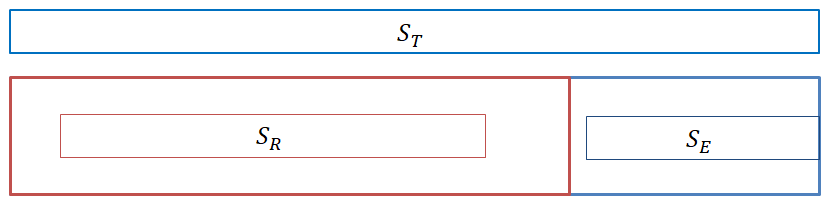
変動は、あるデータが平均値からどの程度ずれているかを評価する量です。\(S_R \)の式を見ると、あるデータに当たるのが、\(\bar{x_j} \) で、平均値が\( \bar{x} \)です。
よって、\(S_R \)は、1列を一つのデータと思った時の、全体の平均値からのずれを評価する量となっています。
つまり、\(S_R \)は条件の変化による変動と言えます。これが、\(S_T \)の殆ど占めていれば、条件を変えた事によって、データの平均値が変化していると考えるのです。
\(S_R \)が\(S_T \)の内占める量を評価するために、以下の量を考えます。
$$\begin{eqnarray}
R^2= \frac{S_R}{S_T } = 1- \frac{S_E }{S_T}
\end{eqnarray}$$
\(R^2 \)が大きい時、条件によって、データの値が変化していると思えそうです。
分散分析
データの平均値が条件によって変化しているか判断するための材料\( R^2 \)を、変動を用いて作りました。
しかし、変動はデータが増えれば無限に大きくなるので、変動だけで判断するのは良くありません。変動をデータ数-1 で割ったものを(不偏)分散と呼びますが、分散を考えれば、データの数に惑わされずにデータが持っている、データをバラつかせる力を評価できます。3変動の分解で出てきた、データ達の自由度や不偏分散は以下の式で書く事が出来ます。
4
$$\begin{eqnarray}
f_T &=& N-1 ,f_R = m-1 ,f_E = N-m \\
V_T &=& S_T /f_T ,V_R = S_R / f_R , V_E =S_E / f_E
\end{eqnarray}$$
\(f_R \)は、1列全体を1つのデータと思っているので、自由度は\(m-1 \)です。\(f_E \)については、
$$\begin{eqnarray}
f_T = f_R + f_E
\end{eqnarray}$$
という要請から計算されています。今比べたいのは、説明できるバラツキと、説明できないバラツキでした。そこで、分散を使って以下の量を考えましょう。
$$\begin{eqnarray}
F= \frac{V_R}{V_E}
\end{eqnarray}$$
この値が大きければ大きい程、条件によってデータの平均値が変化して考えられそうです。5
この量を上手く扱うのが、次から解説するF検定です。6
F検定
上で考えた\(F \)は、適切な仮定の下では、良く知られた確率分布からサンプリングした値になる事が知られています。それについて解説します。
得られている列方向のデータ7は、分散が等しい正規分布から、それぞれ独立に得られているとします。
$$\begin{eqnarray}
x_{ij} \sim \mathcal{N}( \mu _j , \sigma ^{2} )
\end{eqnarray}$$
全ての\(j \)について、\(\mu _j \)が等しいとすると、
$$\begin{eqnarray}
F= \frac{V_R}{V_E}
\end{eqnarray}$$
は自由度\( (f_R , f_E ) \)のF分布に従います。8自由度\(n,m \)のF分布は、以下の式で表されます。
$$\begin{eqnarray}
F(x;n,m)=\frac{1}{B(n/2, m/2)} \left( \frac{nx}{nx+m} \right)^{n/2} \left( 1- \frac{nx}{nx+m} \right)^{m/2} x^{-1}
\end{eqnarray}$$
ただし、\(B(n,m) \)はベータ関数です。表式などは、wikiを見てください。ガンマ関数の親戚みたいなものです。 F分布の表式だけだと意味不明なので、適当なグラフを描いておきます。

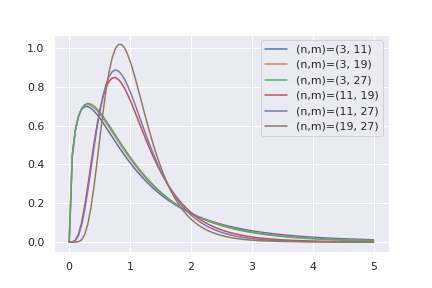
Fを計算しておけば、それと対応するp値を計算する事が出来ます。
有意水準を決めて、統計的仮説検定を行う事で、条件によって平均値が変化したか決める事が出来ます。9この手法はF検定と呼ばれています。
その後、分散分析表と呼ばれるものを書いたりすることもあります。
適当な例題
適当な例に対して一元配置法を使ってみます。普通は、anova と名前の付いたライブラリを使いますが、折角なのでpython で愚直に計算しましょう。
2種類のデータを適当に生成し、一元配置法で平均値が異なることを確かめてみます。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
import pandas as pd
np.random.seed()
#データの生成
df=pd.DataFrame()
df["条件1"] = np.random.normal(loc=1,scale=1,size=30)
df["条件2"] = np.random.normal(loc=0,scale=1,size=30)
#箱ひげ図の描画
df.plot.box()
plt.title("箱ひげ図")
#plt.savefig("boxplot.png")
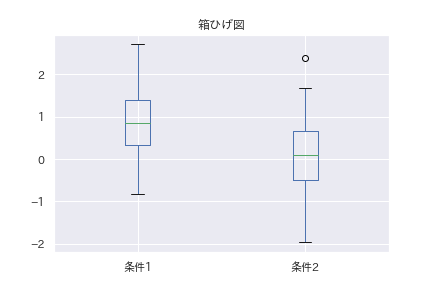
平均0と、1の正規分布からデータをサンプリングしました。ぱっと見でも、平均値に差がある事が分かります。計算を進める為に、平均値を求め、変動を計算します。
mu1 = df.条件1.mean()
mu2 = df.条件2.mean()
X= np.append(df.条件1,df.条件2)
mu = np.mean(X)
print(mu1)
print(mu2)
print(mu)
"""
1.442856447263175
-0.2895218561539811
0.5766672955545967
"""
S_R = len(df.条件1)*(mu1-mu)**2 +len(df.条件2)* (mu2 - mu)**2
S_E = np.sum((df.条件1 -mu1)**2 ) + np.sum((df.条件2 -mu2)**2 )
"""
45.017018792257566
59.35008558312645
"""変動だけを見ると、\(S_E > S_R \)となっています。これは、自由度が
$$\begin{eqnarray}
f_E > f_R
\end{eqnarray}$$
の関係にある為です。自由度を考慮して、分散とFを計算してみます。
f_R =1
f_E = len(X)-f_R -1
V_R = S_R/f_R
V_E = S_E/f_E
print(V_R)
print(V_E)
"""
45.017018792257566
1.0232773376401112
"""
F=V_R/V_E
print(F)
"""
43.992979357948165
"""分散に換算すると、\(V_R > V_E \)であり、\(F\sim 43 \)となっています。これからp値を計算しましょう。
from scipy import stats
p_value = stats.f.sf(F,f_R, f_E)
print(p_value)
"""
1.209867400391656e-08
"""
p値は\(1 \times 10^{-8} \)となり、かなり小さな値です。統計的仮説検定を行うとすると、
$$\begin{eqnarray}
\mu _1 \neq \mu _2
\end{eqnarray}$$
と結論付けることでしょう。因子が2つ以上ある場合は、回帰分析から同じような事をします。詳しい方法は別の記事で解説しています。
まとめ
- 分散分析の説明をした
- 変動の分解の説明をした
- F値の計算を説明した
- python で一元配置法を行った
- 行列でいうと、1列のデータを一つのデータと思った時の変動は、全データの変動と比べてどの程度かを調べるという事です。
- 単回帰の記事で使ってる式です。
- 便宜的にデータをバラつかせる力と表現しているだけで、平均値が変化するか調べられる、という事です。
- \( f_* \)で自由度を表しています。
- 分散を考えると、\( V_T \neq V_R +V_E \)となる事に注意しましょう。
- 適切な仮定を置いた時の話です。
- 条件ごとのデータ
- 計算は気が向いた時に記事にしたいと思います。
- この判断は、有意水準だけ、ミスの可能性を孕んでいる事に注意してください。例えば、\(\alpha = 5%\) の確率で失敗するというのはそれなりに大きな数字です。