



統計学には中心極限定理という大定理があります。データをいっぱい取っておけば大体正規分布になるよという感じに覚えている人も多いのではないのでしょうか。

中心極限定理の内容を解説して、正しく使う例を挙げる記事です。
初めに言葉の準備をします。次に中心極限定理の主張を述べて大筋のの部分を証明します。最後に中心極限定理をpythonで使ってみます。
分布収束
中心極限定理は、確率変数の列の標本平均が、確率変数自信としては良く分からないけど、確率で極限を見ると正規分布と一致するよ、という定理です。この時、一致するという意味をはっきりさせる必要があります。その為に、分布収束(convergence in distribution)という概念を導入します。
[分布収束]
確率変数の列\( \{ U_n \} \)が確率変数\(U \)に分布収束するとは、
$$\begin{eqnarray}
\lim_{n\rightarrow \infty } P(U_n \leq x ) =P(U\leq x )=\int_{-\infty}^x f_U (t) dt =F_{U}(x)
\end{eqnarray}$$
が\( F_U (x) \)の全ての連続点\(x \)1 で成り立つ事です。
\( \{ U_n \} \)が確率変数\(U \)に分布収束する時、\( U_n \rightarrow _{d} U\)で表します。
分布収束するというのは、確率変数\( U_n \) のnを大きくしながら値を得てヒストグラムを描いてみると、段々\(U \)の従う確率分布のヒストグラムに似てくるという雰囲気です。
中心極限定理
上述した分布収束の代表的な応用例が中心極限定理(central limit theorem) らしいです。確率変数たち\(X_1, X_2 , \cdots \) が平均\( \mu \) 分散\( \sigma ^2 \)の確率分布に独立に従う時、\( X_1, X_2 , \cdots \sim i.i.d. (\mu , \sigma ^2 ) \)と表します。また、確率変数の列\( \{ X_1 , \cdots, X_n \} \)の平均を\( \bar{X_n} =\frac{1}{n} \sum_{i=1} ^n X_i \)で表します。
中心極限定理の主張を述べます。
\( X_1, X_2 , \cdots \sim i.i.d. (\mu , \sigma ^2 ) \) とします。この時、
$$\begin{eqnarray}
\lim _{n \rightarrow \infty } P(\sqrt{n} (\bar{X_n} -\mu ) /\sigma \leq x ) = \int_{- \infty} ^{x} \frac{1}{\sqrt{2\pi} }\exp(-t^2 /2 ) dt
\end{eqnarray}$$
となります。つまり、\( \{U_ n = \sqrt{n} (\bar{X_n} -\mu ) /\sigma \} \) は標準正規分布に分布収束します。
この定理の凄い所は、確率変数があれば、どんなものであっても平均を取っていくだけで正規分布になってしまうという所です。仮定が殆ど無くても、正規分布が出てくるという訳で、正規分布は特に大事と言われる所以でもあります。大体の証明をします。
特性関数が標準正規分布の物に収束する事を示して、特性関数が収束すれば、確率分布や、累積分布関数も収束するので、確率変数は分布収束するよという流れで証明されます。2
\(Z_i = (X_i – \mu ) /\sigma \)とすると、\(E[Z_i ] =0 , Var[Z_i ] =1 \)です。3 \(\bar{Z_n} =\frac{1}{n} \sum_{i=1} ^n Z_i \)とすると、
$$\begin{eqnarray}
E[\bar{Z_n } ]&=& 0 \\
Var (\bar{Z_n} )&=& 1/n
\end{eqnarray}$$
です。この記号を使って、
$$\begin{eqnarray}
\lim _{n \rightarrow \infty } P( \sqrt{n} \bar{Z_n} \leq z ) = \int_{- \infty} ^{z} \frac{1}{\sqrt{2\pi} }\exp(-t^2 /2 ) dt
\end{eqnarray}$$
を示せばよい事になります。\(\sqrt{n} \bar {Z_n } \)の特性関数は
$$\begin{eqnarray}
\phi _{ \sqrt{n} \bar {Z_n }} (t)= \left( E[ \exp( Z_1 it/\sqrt{n} ) ] \right) ^n
\end{eqnarray}$$
と書けるので\(Z_1 \)の特性関数を単に\(\phi \)と表すと、\(\sqrt{n} \bar {Z_n } \)の特性関数は、
$$\begin{eqnarray}
\phi _{ \sqrt{n} \bar {Z_n }} =\phi (t/\sqrt{n} ) ^n
\end{eqnarray}$$
と書けます。\(\phi \)をt=0のまわりで2次の項までテイラー展開すると、\( \phi (0) =1 , \phi ^{,} (0) =iE[Z_1]=0 , \phi ^{,,} (0) = E[Z_1 ^2 ] = Var(Z_1 ) =1 \)より、
$$\begin{eqnarray}
\phi (t/\sqrt{n} ) \sim 1- \frac{t^2}{2n}
\end{eqnarray}$$
です。これと、\( \exp \)の定義から、
$$\begin{eqnarray}
\phi _{ \sqrt{n} \bar {Z_n }}(t) =\phi (t/\sqrt{n} ) ^n \sim \left( 1- \frac{t^2}{2n} \right) ^n \longrightarrow _{n\rightarrow \infty } e^{- t^2 /2 }
\end{eqnarray}$$
最後の収束先は、標準正規分布の特性関数です。特性関数が標準正規分布に収束する事が分かったので、\( \sqrt{n} \bar{Z_n } \)は標準正規分布に分布収束します。
最後の一文は真面目に議論しないと本当か分からないですが、詳しくはpdfを読んでください。
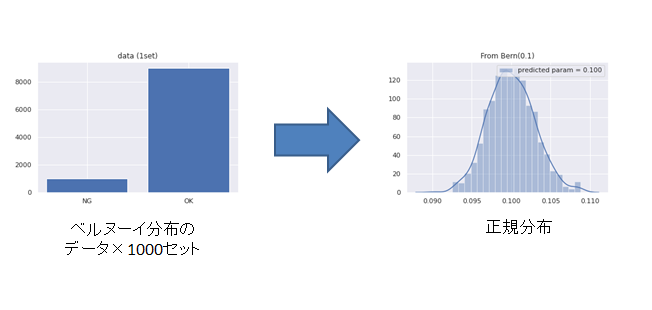
中心極限定理に関する注意は、データを大量にとれば正規分布になると言う人がいる事です。そのような人を見かけても決して話を鵜呑みにしてはいけません。データを大量にとって正規分布になっていたら、それは元々正規分布に従っていただけです。実際、冒頭にあった画像の左側は、ベルヌーイ分布から10000個データをサンプリングしていますが、正規分布とは似ても似つかない形です。
中心極限定理を使ってみる1
簡単な例として、ベルヌーイ分布\( {\rm Ber }(p) \)に従うデータを大量に取得した時に中心極限定理から\( p \)を推定してみます。
初めに、中心極限定理から、nが大きい時には、\( \bar{X_n } \sim \mathcal{N} (\mu , \sigma ^2 /n ) \) となる事に注意します。
例えば、良、不良の2値を取るデータがある時、ベルヌーイ分布\( {\rm Ber }(p) \)の平均値は \(p \) なので、大量のデータの平均値を、大量に取る事で、pの推定が出来ます。4
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
np.random.seed(1)
p=0.1
#ベルヌーイ分布から10000個のデータを1000セット用意
X=np.random.multinomial(10000,pvals=[p,1-p],size=1000)
#pの値を正規分布の平均値として推定
label=np.mean(X[:,0]/10000)
#グラフ描画
sns.distplot(X[:,0]/10000, label= f"predicted param = {label:.3f}" )
plt.title(f"From Bern({p})")
plt.legend(loc='upper right')
plt.savefig("from_bern_to_norm.png")
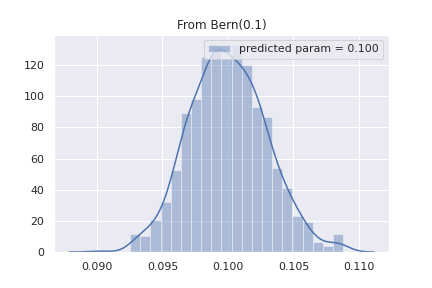
ベルヌーイ分布から正規分布が作られている事、正規分布の平均が0.100と予測されている事が分かります。
中心極限定理を使ってみる2
応用的な話ですが、カイ二乗適合度検定の記事で少しだけ書いた、ガチャの話を例に、中心極限定理を使ってみます。
大体の内容としては、データを多項分布からサンプルしていると仮定するとピアソンのカイ二乗検定統計量がカイ二乗分布に従うという感じです。
詳しい話は上述の記事を読んでもらうとして、問題の設定を書きます。
ガチャはN.R,SR,SSRの4種類あるとして、それぞれの排出確率は\( \pi = ( 0.7,0.25,0.045,0.005 ) \)とします。疑似的にガチャを10000回、1000セット引いたとしてピアソンのカイ二乗統計量を以下の式で計算します。これがカイ二乗分布に従うのか見てみます。
$$\begin{eqnarray}
Q(X|\pi ) = \sum_{i=1}^{4} \frac{ (X_i- 10000\pi _i)^2 }{10000\pi _i}
\end{eqnarray}$$
ただし、\(X_i \)はクラスタに\(i \)に入っているデータの数です。この\(Q \)が\( \chi _{3} ^2 \)に\( n \rightarrow \infty \) の極限で従うことが、中心極限定理から分かっています。
#確率を設定
gatya ={"N":0.7,"R":0.25,"SR":0.045, "SSR":0.005}
#データを取得
p = list(gatya.values() )
X= np.random.multinomial(10000, p,size=1000)
#Qの計算
pi = np.array(list(gatya.values()))
Q= (X-10000*pi)**2/(10000 *pi)
#グラフの描画
sns.distplot(np.sum(Q,axis=1), label="from multinomial")
sns.distplot(np.random.chisquare(3,10000), label="chi square of df=3")
plt.legend()
plt.title("chi square from multinomial")
plt.savefig("chi_from_multinomial.png")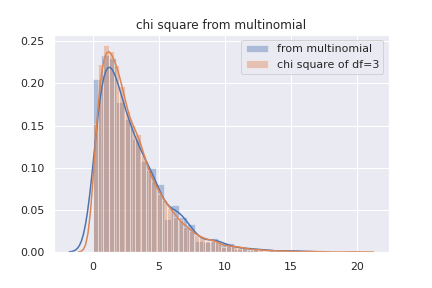
実際にプログラムを動かしてみると、多項分布からサンプルして計算されたQのヒストグラムは、カイ二乗分布と殆ど同じ形をしている事が分かります。5 つまり。中心極限定理によって、Q値がカイ二乗分布に従っています。
まとめ
- 分布収束の定義をした
- 中心極限定理の主張を述べた
- 中心極限定理の証明の概要を説明した
- 中心極限定理を使ってみた
- 連続点とは、\( \lim_{x\rightarrow a} F_U (x) =F_U (a) \) が成り立つ点です。
- 後半が微妙な所で、積分と極限の交換などを真面目に考える必要があります。レヴィの連続性定理とか呼ばれています。例えば、http://www.math.u-ryukyu.ac.jp/~sugiura/2011/prob2011b02.pdfに証明があります。
- Var() は分散を取るという意味です。
- 最尤推定しろという突っ込みは無しで
- 普通は、出所の分からないデータに対して\( \pi _i \)を設定して、Qを計算して検定を行うのですが、中心極限定理を感じるにはいい例かなと思います。