



械学習モデルを組んだ時、モデルの良し悪しはトレーニングデータへの適合(train loss)とテストデータへの適合(validation loss)の差が良い指標になります。
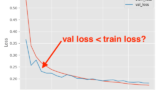
モデルの学習の際、Validation Loss <Train Loss となって、なんだこりゃ?となった経験はないでしょうか。 1 時々起こる現象で、気にはなっていたのですがテスト用のデータで試すとうまくいっていたので深くは考えていませんでした。


先日、Twitterの投稿にその疑問を解決してくれる物があったので共有したいと思います


状況のセットアップ
使うモデルはMiniVGGNet2 と呼ばれる物です。CNN(畳み込みニューラルネットワーク)が3層繋がっているイメージのモデルです。3以下の構成になっています。
1層目
畳み込み→ReLU→B.N.→畳み込み→ReLU→B.N.→MaxPooling→DropOut
2層目
→ 畳み込み→ReLU→B.N.→畳み込み→ReLU→B.N.→MaxPooling→DropOut
3層目
→ 全結合→活性化→B.N. →DropOut→全結合→SoftMax
1層目の畳み込みサイズが32、2層目の畳み込みサイズは64です。
プーリングはサイズはいつも2×2です。
B.N.はバッチノーマリゼーションを表しています。この層は、入ってきたデータを正規化4する層です。
勾配逆伝搬の特徴で、出力に近ければ近い程パラメーターの更新が早くなり、入力側のパラメーターは殆ど変わらないという状態になります。出力側ばかり学習が進まないようにする為の手法です。詳しい説明は、原論文5を読んでください。
https://arxiv.org/pdf/1502.03167.pdf
使うデータはfashion mnistです。Tシャツとか、パンツとかのドット絵10種類からなるデータです。
初めにモデルをトレーニングし、トレーニングデータよりテスト用のデータの方がロスの値が小さくなっている事を確認しましょう。
MiniVGGNet の実装は本家や、Google先生からコードをもらってください。
GPU無しだと学習にめっちゃ時間がかかるので、Google Colab を使う事をお勧めします。以下の記事で使い方を解説してます。

下のコードを実行すると、モデルの作成まで進みます。
from pyimagesearch.minivggnet import MiniVGGNet
from sklearn.metrics import classification_report
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
NUM_EPOCHS = 25 #エポック数, 重いので10とか推奨
INIT_LR = 1e-2 #学習率
BS = 32 #batch size
trainX = trainX.reshape((trainX.shape[0], 28, 28, 1))
testX = testX.reshape((testX.shape[0], 28, 28, 1))
trainY = to_categorical(trainY, 10)
testY = to_categorical(testY, 10)
labelNames = ["top", "trouser", "pullover", "dress", "coat",
"sandal", "shirt", "sneaker", "bag", "ankle boot"]
opt = SGD(lr=INIT_LR, momentum=0.9, decay=INIT_LR / NUM_EPOCHS)
model = MiniVGGNet.build(width=28, height=28, depth=1, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
下のコードを実行すると、モデルをトレーニングしてグラフを出力します。6
H = model.fit(trainX, trainY,
validation_data=(testX, testY),
batch_size=BS, epochs=NUM_EPOCHS)
H = pd.DataFrame(H.history)
epochs = np.arange(0, len(H["loss"]))
plt.plot(epochs, H["loss"], label="train_loss")
plt.plot(epochs, H["val_loss"], label="val_loss")
plt.title("Loss Plot")
plt.xlabel("Epoch #")
plt.ylabel("Loss")
plt.legend()
#plt.savefig("Loss.png")
plt.show()
以下のような出力が得られたと思います。確かに、トレーニングの方が大きなLossを示しています。

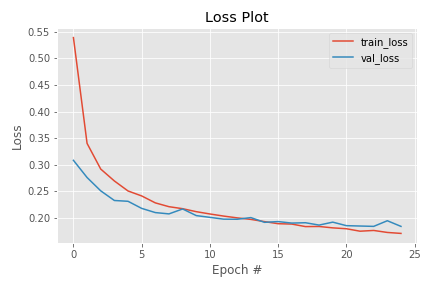
Validation Loss <Train Loss が起こる理由
上で見たように、Training のLossよりValidation のLossの方が小さくなるという現象は遭遇したことがあると思います。以下のような理由が考えられるようです。
- 正則化には、Trainingの時だけ適用されるものがある。
- Training Lossは1エポック中計算され、Validationは1エポック終了時に計算される。
- Validation に、Training より簡単なデータが集まっている。(サンプルの偏りがある)
確かに、と思うものばかりです。
それぞれを解説し、1,2については簡単に検証してみます。
1 .”正則化には、Trainingの時だけ適用されるものがある”
正則化は、例えば\( L^2 \) 正則化やDropOutがあります。DropOutに関しては、Training 時にモデルのノードを削除するだけで、Validation では全ノードを使用します。つまり、Training のモデルの方が不利な状況で答えを導かなくてはなりません。その為、良いモデルが出来ている時は多少Validation が有利かもしれません。
実際に miniVGGNet から dropoutの層を消去して学習させた結果を載せます。7

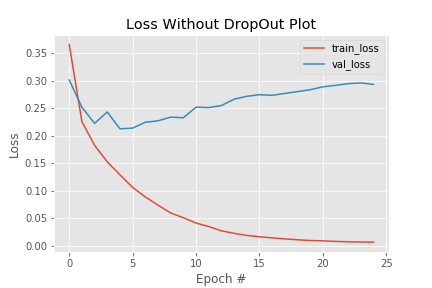
殆どのエポックでTraining Loss < Validation Loss となりました。Training もValidation も同じモデルで競わせたら、何回も見ているTraining の方が予測しやすいのは当たり前ですね。
しかし、Validation Lossが殆ど下がっていないので過学習しています。8 汎化性能を追い求めるあまり、表現力が全く足りないと感じる時以外は、敢えて正則化の層を削除する事はお勧めしません。
2. “ Training Lossは1エポック中計算され、Validationは1エポック終了時に計算される”
練習の成果をValidation で発揮しているイメージなので、Training のグラフを描く時の軸を少し弄って、Trainingのグラフを左側にずらしてみましょう。
H = pd.Dataframe(H.history)
epochs = np.arange(0, len(H["loss"]))
(fig, axs) = plt.subplots(2, 1)
plt.style.use("ggplot")
axs[0].plot(epochs, H["loss"], label="train_loss")
axs[0].plot(epochs, H["val_loss"], label="val_loss")
axs[0].set_title("Unshifted Loss Plot")
axs[0].set_xlabel("Epoch #")
axs[0].set_ylabel("Loss")
axs[0].legend()
axs[1].plot(epochs - 0.5, H["loss"], label="train_loss") #0.5エポックだけずらす
axs[1].plot(epochs, H["val_loss"], label="val_loss")
axs[1].set_title("Shifted Loss Plot")
axs[1].set_xlabel("Epoch #")
axs[1].set_ylabel("Loss")
axs[1].legend()
plt.tight_layout()
#plt.savefig("LossvsShiftedLoss.png")
plt.show()

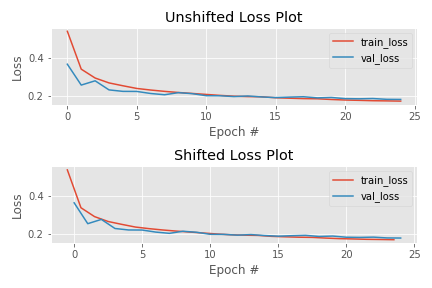
上のグラフが生のグラフで、下のグラフが軸を弄ったグラフです。乖離が小さくなっています。Training とValidation でLossの計算が違う事を修正するのは、グラフの見た目には効果があるようです。
3. Validation に、Training より簡単なデータが集まっている。(サンプルの偏りがある)
3. は、あるあるでは無いでしょうか。
簡単なデータが集まることは少ないかもしれませんが、それぞれおのデータが別の分布からサンプルされているという事は多いと思います。データを振り分ける際には、以下の事に注意が必要です。
トレーニングデータとテストデータは同じ分布からサンプルする
例えば、工場で何かを作ろうとしている時に、季節によって値が大きく変動する事が分かっている特性値に対して、トレーニング用は春夏秋からサンプリングし、テスト用は冬のみからサンプリングした場合はあまり上手くいかないでしょう。
トレーニングデータとテスト用データの難易度を揃える
例えば、トレーニング用は今までの全てのデータ、テスト用は新しく特徴量を加えた未知のデータだとあまり上手くいきません。このような場合は、トレーニング時点で新しい特徴量に対して、モデルは無知です。
データのリーク(“data leakage”)はないか?
答えに直結する値が特徴量に入っている事を指します。
例えば、車の燃費を予測したいとします。試験データを取るために、色々な車が一定の油量で走る実験を行うでしょう。その時、特徴量に走行量が入っていると、おしまいです。
3つの指摘がありましたが、一番効いているのは1つ目の汎化性能を出すために、敢えてTraining しにくくする技を使う事にあるように感じます。1. , 2. の理由によってLoss < Train となっているのなら、殆ど気にする必要が無いという確認にもなりました。
3.の疑いがあるなら、それはデータを修正しなくてはなりません。
まとめ
- Train Loss > Validation Loss となる状況を再現した。
- そのような状況が起こり得る原因を3つ挙げた
- データに問題がないなら、 Train Loss > Validation Loss はあまり気にしなくても良い
- 自分の経験では、ゼロから作るディープラーニングで、ドロップアウトを実装した時とかに起こったような気がします。
- もっと単純なモデルでも良いんですが、元ネタをリスペクトしてモデルは合わせます。
- 一応CNNの記事があります。
- 平均を引いて分散で割る
- 気が向いたら解説記事を書きます。2015年に発表された手法なのに浸透しているので、効果が大きいのでしょう。
- Google Colab のGPUで1エポック20~30秒かかります。
- DropOutのLoss をval_lossに加えられれば一番良いのですが、やり方が分からなかったので荒業です。
- このくらいで済んでいるのはB.N. 様様です。