



既存手法をカーネル法にする手法の事をカーネル化と呼びます。
この手法では既存手法の計算を流用して、表現力の高いモデルを作ることが出来ます。カーネル化において自分がやる必要があることは、カーネルの設計だけだけです。
カーネル化を理解するための例として、ロジスティック回帰とリッジ回帰を使います。
カーネル化した手法で、カーネルを変えるとモデルがどう変わるか実験してみます。
カーネル法の入門記事があるので読んでみてください。カーネルとはそもそも何か、についての記事もあるのでどうぞ。



リッジ回帰のカーネル化
リッジ回帰分析の復習はこちらからどうぞ。

未知のデータの組を\( (y, x ) \)として、既に持っているデータを行列\( X \)と \(\vec{y} \)とします。リッジ回帰のモデルと誤差関数は以下です。
$$\begin{eqnarray}
y&=&\vec{\beta} \cdot \vec{x} \\
S &=& \|\vec{y}- X \vec{\beta} \|^2 +\lambda \| \vec{\beta} \| ^2
\end{eqnarray} $$
Sを最小化するパラメーター\( \vec{\beta} \)を求めることで予測式をたてました。
カーネルを \( K=\{ k_{ij} \} = k (\vec{x_i} , \vec{x_j}) , \vec{k}(x)_i = k(x, x_i ) \) で表します。カーネルリッジ回帰のモデルと誤差関数は以下の式です。
$$\begin{eqnarray}
y_K &=& \vec{\alpha} \cdot \vec{k}(x)\\
S_k &=& \|\vec{y}- K \vec{\alpha} \|^2 +\lambda \vec{\alpha} ^{T} K \vec{\alpha}
\end{eqnarray} $$
リッジ回帰とカーネルリッジ回帰の式を比べます。初めにモデルを見ましょう。
モデルの違いは、未知データ\(\vec{x} \)をそのまま使うか、カーネルによるベクトル \(\vec{k} (x) \) を使うかの違いです。
誤差項の部分を見ましょう。
2乗誤差の部分は、モデルの違いだけです。 \( L^2 \)項によるペナルティは、 このままでは良く分かりません。内積は、計量と呼ばれる行列で書けた事を思い出しましょう。
\begin{eqnarray}
\ \| \vec{\beta} \| ^2&=& \vec{\beta } ^{T} I \vec{\beta } \\
\| \vec{\alpha} \| _K ^2 &=& \vec{\alpha } ^{T} K \vec{\alpha }
\end{eqnarray}
上の式を比べると、リッジ回帰の場合は計量として単位行列を使い、カーネル化した時は、計量としてカーネルを使っていることが分かります。
行列を使って定義する事が出来たことを忘れた方はこちらの記事をどうぞ。
リッジ回帰をカーネル化することで、見かけ上は誤差関数やモデル式が大きく変わったように見えます。しかし、カーネル化するというのは、以下の2つの事を行うだけです。
- データを使って計算している部分は、カーネル行列、ベクトルに変える
- 内積は、計量 1 をカーネル行列に変える。
この議論を踏まえて、ロジスティック回帰をカーネル化してみましょう。ロジスティック回帰の復習をしておきたい人はこちらを先にどうぞ。

ロジスティック回帰のカーネル化
ロジスティック回帰のモデルは、以下の式でした。
$$\begin{eqnarray}
y &=& \sigma( \vec{w} \cdot \vec{x} ) \\
L &=& -\sum ( y_i \ln \sigma( \vec{w} \cdot \vec{x_i} ) + (1-y_i)\ln ( 1- \sigma( \vec{w} \cdot \vec{x_i} ) )
\end{eqnarray}$$
ただし
$$\begin{eqnarray}
\sigma(x) = \frac{1}{1+\exp(-x) }
\end{eqnarray}$$
このモデルをカーネル化するにはどうしたら良いでしょう?
注目すべきは、全データX と全ラベル\( \vec{y} \)に対しては、モデルは次のようになる事です。
$$\begin{eqnarray}
\vec{y} &=& \sigma( X \vec{w} )
\end{eqnarray}$$
ベクトルを指数関数にいれると、ベクトルの成分毎の指数関数とが出てくるいう事にしてください。カーネル化したかったらXとKを入れ替えろという事で、カーネル化したモデルは以下のようになります。
$$\begin{eqnarray}
\vec{y} &=& \sigma( K \vec{w} )
\end{eqnarray}$$
i番目のデータの予測式は、Kのi列目のベクトル2 を\(\vec{K_i} \)として、
$$\begin{eqnarray}
y_i &=& \sigma( \vec{K_i} \cdot \vec{w} )
\end{eqnarray}$$
です。これをロジスティック回帰の誤差関数にいれて、カーネルロジスティック回帰のモデルは以下になります。
$$\begin{eqnarray}
\vec{y} &=& \sigma(K \vec{w} ) \\
L &=& -\sum ( y_i \ln \sigma( \vec{w} \cdot \vec{K_i} ) + (1-y_i)\ln ( 1- \sigma( \vec{w} \cdot \vec{K_i} ) )
\end{eqnarray}$$
パラメーターの勾配の計算に関して言えば、カーネル化の前後で計算方法は全く変わりません。全データXを選んできたカーネルKに変えるだけです。
お手軽にカーネルを取り換えて計算できるので、数種類のカーネルで実験してみましょう。カーネルのパラメーターの調整は適当なので、それぞれのカーネルのベストな結果を出しているわけではありませんのでご注意を。
カーネル化の実験
おなじみのtitanic 号データで実験してみましょう。ロジスティック回帰の精度を基準値として、カーネルロジスティック回帰が効果ありなのか判断してみましょう。
初めに、使うカーネルを紹介しておきます。
1.線形カーネル
$$\begin{eqnarray}
k(x,y) =x \cdot y
\end{eqnarray}$$
2.RBFカーネル(ガウシアンカーネル)
$$\begin{eqnarray}
k(x,y) =\exp(\gamma \| x-y \|^2 )
\end{eqnarray}$$
3.フィッシャーカーネル
$$\begin{eqnarray}
k(x,y) = s(x|\theta) \cdot s(y|\theta)
\end{eqnarray}$$
ただし、\( s(x|\theta ) \) はFisher スコア 3
Fisher スコアを知らない人はこちらをどうぞ。統計量の推定の精度に関する大事な量です。
結果を貼ってしまいます。



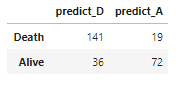

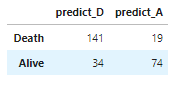

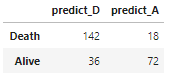
行列の対角成分が大きい程正確な予測をしているわけですが、ロジスティック回帰が一番駄目です。カーネル法は大体似たり寄ったりな感じになっています。パラメーターをしっかり調整すればそれぞれのカーネルの個性が表れてくるでしょう。正直、Fisher カーネルはどうなるのか全く予想できなかったので、案外良い結果で驚いています。
まとめ
- 既存手法をカーネル化出来る。
- カーネル化とは、生データをカーネル行列やベクトルに置き換える作業の事。
- カーネル化することで、モデルの表現力が向上する、
- 使うカーネルは、自分で選ぶ必要がある。
次に読むべき記事はこちらです。