
予測したい値が連続値でなく、離散的な値だったり名前だったりすることがままあります。そのような問題を分類問題と言います。分類問題の手法を紹介します。
ロジスティック回帰とは
ロジスティック回帰は説明変数から0か1を出力する手法です。AかBかを予測したいときは、0ならA, 1ならBと問題を読み替えて手法を適用します。答えが2種類の時と3種類以上の時で若干手法が違います。有名なirisデータ(アヤメの分類データ)にロジスティック回帰を適用してみましょう。
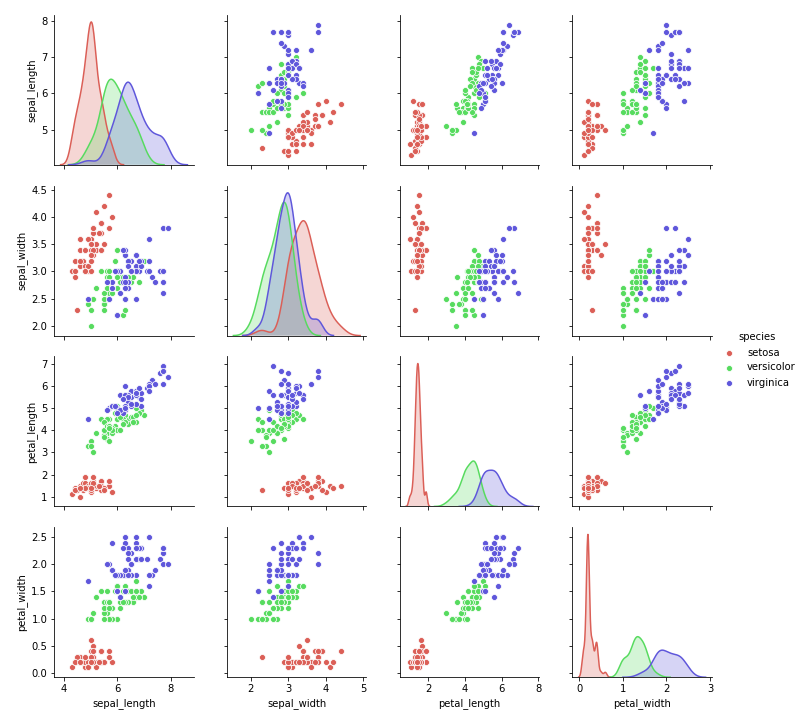
花の形を表す4つの説明変数 から種類(species)を予測します。species は3種類あります。各変数に対する分布をみると以下のようになっています。
データを (学習用:テスト用)=7:3で分けてロジスティック回帰を適用すると、以下のような結果が得られます。
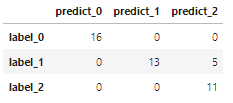
label_0 などは正解のラベルを表し、predict_0 などはロジスティック回帰で予測したラベルを表します。行列の対角成分以外がすべて0なら完璧に予測できていることになります。今回のモデルでは、label_1 が正解なのを、2と予測した結果間違ってしまったデータが5つあることが分かります。
2値分類の場合のロジスティック回帰
2値分類の場合のロジスティック回帰の式を導出します。問題設定としてはラベルとデータ[mathjax]\( (t_i, \vec{x}_i)\) が与えられているとして、データ [mathjax]\( \vec{\tilde{x}} \)に対応するラベルを予測するというものです。初めは、ラベル2値の場合を考えましょう。
初めに問題になるのは、どうやって0か1しかとらない関数を作るかですが、便利な関数があります。
[mathjax]$$\begin{eqnarray}
\sigma (x) =\frac{1}{1+\exp (-x)}
\end{eqnarray}$$
この関数はシグモイド関数と呼ばれ、0以上1以下の値を取ります。グラフは以下のようになります。
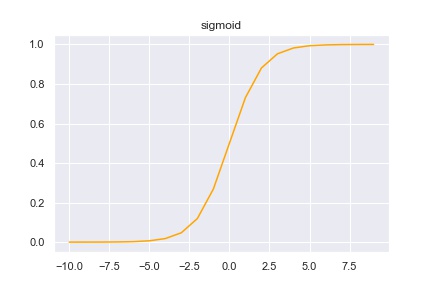
ラベルが2種類の時は、1 \(\sigma (x) \) と\(1-\sigma (x) \)の値を比べて、\(\sigma(x) \)の方が大きければラベル0 を正解とします。式で書くと以下のようになります。
$$\begin{eqnarray}
t={\rm argmax} (\sigma (x), 1-\sigma (x) )
\end{eqnarray}$$
ただし、argmax は、値が最大の成分の位置を返す関数と思っています。
重回帰分析の時のように、パラメーター\( w_0 ,w_1, \cdots , w_n \)を導入します。\(w_0 \)に定数項のような役割をさせる為に、説明変数に1という定数を作っておきます。つまり、
$$\begin{eqnarray}
\vec{x} &=& ( 1, x_1, \cdots ,x_n) \\
\vec{w} &=& (w_0, w_1, \cdots , w_n)
\end{eqnarray}$$
とするという事です。
ロジスティック回帰とは、以下のモデルの事です。
$$\begin{eqnarray}
t_i = \sigma (\vec{w} \cdot \vec{x_i} )=\frac{1}{1+\exp (- \vec{w} \cdot \vec{x_i} )}
\end{eqnarray}$$
最尤法で、パラメーター\(w_i \)たちを決める事が多いです。
尤度と最尤法
尤度と最尤法について、簡単に説明をします。詳しい説明は、以下の記事でしています。

データ\(X \)と、確率分布\(p(-| \theta )\)を固定した時のパラメーター\( \theta \)に関する関数
$$\begin{eqnarray}
L(\theta )= \prod _{x_i \in X } p(x_i |\theta )
\end{eqnarray}$$
を尤度と呼びます。負の対数尤度を代わりに考える事が多いです。
データとして大量に取得されている値の時に、\(p(x_i |\theta ) \)の値が大きいという事は、確率分布がデータを表現しているという事です。2パラメーターを決める基準として、尤度を採用すれば、尤度を最大化する事で、確率分布をデータに適合させることが出来ます。
尤度を最大化する事で、確率分布のパラメーターを決める手法を最尤法と言います。
大体の場合は、尤度をパラメーターで微分して0となるパラメーターを求めます。解析的に計算出来ない場合は、勾配法を使います。以下のようにパラメーターを更新する手法です。
$$\begin{equation}
\theta _{new} = \theta + \eta \nabla _{\theta} L(\theta )
\end{equation}$$
\( \eta \)は、学習率と呼ばれ、0から1の間の適当な数字です。
ロジスティック回帰の場合にも最尤法を使う為に、もう少し説明します
ベルヌーイ試行(分布)を考えます。つまり、t=1 となる確率がp , t=0 となる確率が(1-p) となるような事象を考え、それをN回繰り返したとします。3i番目に\( t_i \)が出る確率を\(P_i \)は以下の式で表せます。
$$\begin{eqnarray}
P_i = p^{t_i} (1-p)^{t_i -1 }
\end{eqnarray}$$
この場合の尤度を考えます。
$$\begin{eqnarray}
L(p) = \prod _{i} P_i = \prod _{i} p^{t_i} (1-p)^{1-t_i }
\end{eqnarray}$$
負の対数尤度は以下のようになります。
$$\begin{equation}
L(p ) = -\sum_i (t_i p +(1-t_i )(1-p)
\end{equation}$$
この形の関数は、交差エントロピー誤差とも呼ばれます。
ここで、\( p(w|x_i ) = \sigma (\vec{w} \cdot \vec{x_i }) \)と置くと、ロジスティック回帰の場合でもベルヌーイ分布が考えられます。
負の対数尤度は以下のように書けます。
$$\begin{eqnarray}
L(\vec{w} ) = -\sum_{i} (t_i \sigma (\vec{w} \cdot \vec{x_i} )+( 1-t_i ) (1-\sigma (\vec{w} \cdot \vec{x_i} )
\end{eqnarray}$$
が出てきます。つまり、(ラベルが0である確率) \( = \sigma ( \vec{w} \cdot \vec{x_i} ) \)という状況を考えていることと同じです。
ロジスティック回帰で、交差エントロピー誤差を最小にするのは、ラベルの出現を予測する確率分布を作ろうとしているのと同じ事、という訳です。
\(L\) を最小にするパラメーターを求めるには、\(L \)の微分が必要です。
[mathjax]$$\begin{eqnarray}
\nabla _w L &=& -\sum ( t_i \vec{x_i} – \sigma (\vec{w} \cdot \vec{x_i}) \vec{x_i} ) \\
&=& \sum \vec{x_i} \left( \frac{1}{1+ \exp (-\vec{w}\cdot \vec{x_i }) } – t_i \right)
\end{eqnarray}$$
\( \nabla _w \)は\( \vec{w} \)で勾配を取る操作です。
この式を使って、勾配法で最適なパラメーターを探します。2値分類の場合はこれで終わりです。3種類以上の場合も、同じように考えられます。
多クラス分類
現実では3種類以上に分類する必要があることが多いです。例えば、車の形や排気量から製造メーカーを当てようと思ったら、ラベルの数は2種類では絶対に足りません。4
単回帰分析を重回帰分析に拡張するのと同じように、ベクトルと行列を使います。
クラスの数をKとしましょう。クラスkのラベル \( t \)は、k番目以外の成分が全て0のベクトルとして以下のように表します。
$$\begin{eqnarray}
t =(0, \cdots, 0,1,0,\cdots, 0)
\end{eqnarray}$$
2値ロジスティック回帰の場合と同様に話をする為に、以下の量を定義します。
$$\begin{eqnarray}
a_{ik} &=&\vec{w_k} \cdot \vec{x_i} \\
\pi _{ik} &=& \frac{\exp (a_{ik}) }{\sum_{j}^{K}\exp (a_{ij} )}
\end{eqnarray}$$
\( \vec{w_k} \) がラベル \( k\)に関するパラメーターです。5
予測値は、\( \pi_{ik} \)の \( k\)を動かして、確率が最大となる \(k\) をi番目のデータの予測ラベルとします。つまり、以下のようなモデルを考えています。
$$\begin{eqnarray}
t_i = {\rm argmax} \left( \pi_{i1} , \cdots , \pi_{iK} \right)
\end{eqnarray}$$
(K=2 \)の時は、2値ロジスティック回帰と同じになることを確認してみてください。
各パラメーターは \( \vec{w_k} \) での勾配を取って、負の対数尤度\(L\) が最小となるように決めます。解析的には解けない式がまたしても出てきます。
交差エントロピーと、勾配の式だけ書いておきます。
$$\begin{eqnarray}
L(w) &=& -\sum_{i} \sum_{k} t_{ik} \ln (\pi_{ik}) \\
\nabla _{w_j} L &=& \sum_{i} \left( \pi_{ij} – t_{ij}) \right) \vec{x_i}
\end{eqnarray}$$
またしても、勾配法などで、パラメーターを決定します。ロジスティック回帰でシグモイド関数が使われるのは、勾配の手計算が簡単な為です。
ロジスティック回帰も線形回帰?
ロジスティック回帰は、重回帰分析よりも関数が複雑です。しかし、核となる部分はパラメーター\(w \)とデータ\(x\)の内積を取る部分です。
$$\begin{eqnarray}
w\cdot x = \sum w_i x_i
\end{eqnarray}$$
他の部分は、既に出来ている関数で値を得るだけなので、人間が決める部分です。数学的な手続きが必要な部分は線形なので、ロジスティック回帰も線形回帰という事が出来ます。このような意味で、一般化線形モデル(GLM ;Generalized Linear Model )と呼ばれたりします。
この考え方に立つと、線形回帰の誤差関数を色々な確率分布6にしてみたり、\(w\cdot x \)を別の関数で飛ばしたりと、色々なモデルを考える事が出来ます。
まとめ
- ラベルを予測するための手段としてロジスティック回帰がある。
- 誤差関数は交差エントロピー誤差が使われる。
- ロジスティック回帰では、確率で予測するべきラベルを表す。
- ラベルが3種類以上の時はラベルをベクトル表示して、確率が最も大きい場所を予測値にする。
- 一般化線形モデルの考えを紹介した。
