
ベイズ統計学の記事で、ベイズの定理を用いた、確率分布のパラメーターの推定について書いていました。パラメーター推定では、どの程度の誤差を持つのかまで推定出来ました。普通の統計学的な手法でパラメーターを推定すると、どの程度正確なのか解説します。そのカギになるのがFisher 情報量(Fisher 情報行列)です
ベイズ統計学によるパラメーター推定の記事はこちら。

尤度と最尤推定法
xを確率変数として、xの情報を知りたいとしましょう。未知のパラメーター \( \theta \) によって確率分布が定まっているとしましょう。 つまり、\( p(x| \theta) \) を求めたい状況にあるとします。そんな時、\( p(x| \theta ) \) のことを尤度と呼びます。
どうやって \( \theta \) を決めたらいいでしょうか。一つの方向として、尤度を最大化する方向があります。大体の問題では、対数尤度\( L= \ln p(x|\theta ) \)を考えます。
つまり、以下の関係を満たす\( \hat{\theta} \)を求めます。
$$\begin{eqnarray}
\nabla _{\theta} L = 0
\end{eqnarray} $$
この式の解\( \hat{\theta} \)で、尤度を最大にするものを、最尤推定量と呼びます。最尤推定量を求める手法を最尤法とか最尤推定と言います。
\( \hat{\theta} \)が満たす条件によって、名前が付いていたりします。
$$\begin{eqnarray} E[\hat{\theta} ]_{p(x| \theta ) } =\theta
\end{eqnarray} $$
となる推定量を不偏推定量と呼びます。
それぞれが独立で、同じ分布に従うデータが\( \mathbf{X}= ( x_1 , \cdots , x_N ) \)の N個 あるとして、
正規分布\( \mathcal{N}(x| \mu ,\lambda ^{-1} ) \) と、ポアソン分布1\( \mathcal{P}(X |\lambda)= \exp(-\lambda ) \frac{ \lambda^{x} }{x !} \) で最尤推定を行ってみます。
正規分布はパラメーターが2つあるので、それぞれについて最尤推定を行います。正規分布とポアソン分布は以下のような形をしています。

正規分布について
$$\begin{eqnarray}
L &=& \frac{N}{2} \ln (\lambda ) -\sum \frac{1}{2}\lambda (x_i- \mu )^2 +const \\
\frac{\partial}{\partial \mu } L &=& \lambda \sum (x_i-\mu ) \\
\frac{\partial}{\partial \lambda } L &=& \frac{N}{2 \lambda } – \frac{1}{2} \sum (x_i -\mu)^2
\end{eqnarray} $$
それぞれの最尤推定量を求めると、以下になります。
$$\begin{eqnarray}
\hat{\mu} &=& \frac{\sum x_i}{N} \\
\hat{\lambda}^{-1} &=& \frac{1}{N} \sum (x_i – \hat{\mu} )^2
\end{eqnarray} $$
\( \mu =10 ,\sigma =10 \)から サンプリングし、最尤推定をしてみましょう。サンプル数が増えると、真の値に近付くでしょうか。
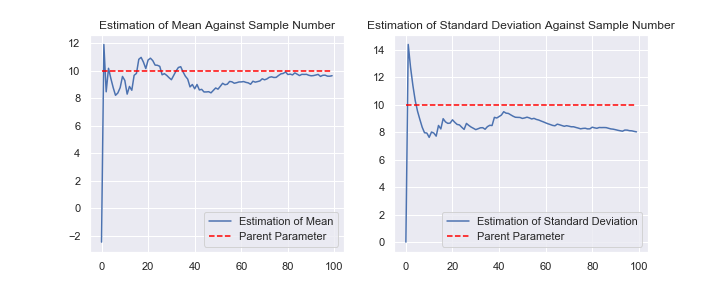
最尤推定で得られた平均値は不偏推定量ですが、分散は不偏推定量 ではありません。 分散の不偏推定量は、 \( \sigma ^2 = \frac{1}{N-1} \sum (x_i – \hat{\mu} )^2 \) です。 真の値とは違う所へ収束しているのはそれが理由です。
ポアソン分布について
$$\begin{eqnarray}
L &=& -N \lambda + \sum x_i (\ln \lambda -1 ) \\
\frac{\partial}{\partial \lambda } L &=& -N + \frac{1}{\lambda} \sum x_i
\end{eqnarray} $$
\( \lambda \)について解くと、以下のようになります。
$$\begin{eqnarray}
\hat{ \lambda} = \frac{1}{N}\sum x_i
\end{eqnarray} $$
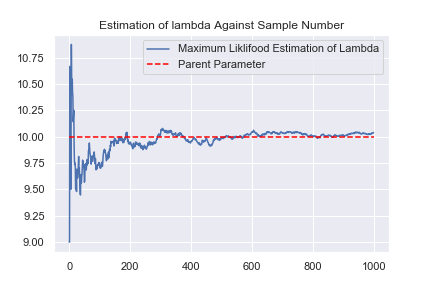
ポアソン分布は、平均値と分散が一致していて、最尤推定量が不偏推定量になっています。1000個のサンプリングによって、真の値を推定できるようになっています。
推定した不偏推定量の分散はどのくらいなのでしょうか。不偏推定量の平均値は求めたいパラメーターに一致するので、分散を限りなく小さく出来るとうれしいです。しかし、実験の結果を見て分かるように、推定値は常に波打ち、分散を常に持っている事が分かります。波の高さがだんだん小さくなっていることも分かりますが。
不偏推定量の分散についての情報を与えてくれるのがFisher 情報量です。
Fisher 情報量の定義
最尤推定によると、パラメーターは\( L_{\theta} = \frac{\partial}{\partial \theta} L = \frac{1}{p(x|\theta)}\frac{\partial}{\partial \theta} p(x|\theta ) \)から求めているので、この量を調べてみるのが良さそうです。この量をFisher スコアと呼びます。期待値と分散を求めましょう。2
$$\begin{eqnarray}
E[L_{\theta} ]&=& \int \frac{1}{p(x|\theta)} \frac{\partial p(x|\theta )}{\partial \theta} p(x|\theta ) dx \\
&=& \frac{\partial}{\partial \theta} \int p(x|\theta ) dx =0 \\
V[L_{\theta} ]&=& E[(L_{\theta})^2 ] – (E[L_{\theta} ])^2 = E[(L_{\theta})^2 ]
\end{eqnarray} $$
\( E[(L_{\theta})^2 ] \)をFisher 情報量と呼び、\(I_{\theta} \)と書きます。対数尤度に関して、次の式に注意しましょう
$$\begin{eqnarray}
\frac{\partial ^2}{\partial \theta^2} L =- (\frac{ \partial}{\partial \theta}L)^2 +\frac{1}{p(x|\theta )} \frac{\partial ^2} {\partial \theta ^2}p(x|\theta )
\end{eqnarray} $$
この式を用いると、Fisher 情報量を書き換えられます。
$$\begin{eqnarray}
I_{\theta} &=& E\left[ L_{\theta} ^2 \right] =- E\left[ \frac{\partial ^2}{\partial \theta^2} L \right] &=& V[L_{\theta}]
\end{eqnarray} $$
正規分布のように、パラメーターが2つ以上ある場合は、以下で定義される行列を考えます。
$$\begin{eqnarray}
{I_{\theta}}_{i j} = – E\left[ \frac{\partial ^2 L}{\partial \theta _i \partial \theta _j} \right] \end{eqnarray} $$
この時、Fisher 情報量は Fisher 情報行列とも呼ばれます。まだ意味は分かりませんが、Fiser 情報量を求めてみましょう。データN個から計算するFisher情報量を\( I_{N} (\theta ) \)と書きます。
正規分布について
$$\begin{eqnarray}
L &=& \frac{N}{2} \ln (\lambda ) -\sum \frac{1}{2}\lambda (x_i- \mu )^2 +const \\
\frac{\partial ^2 L}{\partial \mu ^2 } &=& -N \lambda \\
\frac{\partial ^2 L}{\partial \lambda ^2 } &=& -\frac{N}{2 \lambda ^2} \\
\frac{\partial ^2 L}{\partial \lambda \partial \mu } &=& \sum ( x_i – \mu )
\end{eqnarray} $$
と計算できます。行列の対角成分には\(x_i \)が存在しないので、期待値をとってもそのままです。対角成分以外の期待値は\( \int \sum(x_i -\mu)p(x_i ) dx_i = N\mu – N\mu =0 \)となります。
$$\begin{eqnarray}
I_{N} (\theta) = \begin{pmatrix}
N\lambda & 0 \\
0 & \frac{N}{2\lambda ^2}
\end{pmatrix}
\end{eqnarray} $$
ポアソン分布について
$$\begin{eqnarray}
L &=& -N \lambda + \sum x_i (\ln \lambda -1 ) \\
\frac{\partial ^2 L}{\partial \lambda ^2} &=& -\frac{1}{\lambda ^2} \sum x_i \\
I_N (\theta) &=& \frac{N}{\lambda }
\end{eqnarray} $$
計算してみると、Fisher情報量には分散の値ばかり出てきています。尤度の微分の分散を計算しているので当たり前ですが。この量が、不偏推定量の分散に関わっています。
Fisher 情報量とクラメール・ラオの不等式
大事な雰囲気が出ているFisher 情報量ですが、意味を解き明かしてみましょう。\(\hat{\theta} \)を\( \theta \) の不偏推定量とします。つまり、以下が成り立つわけです。
$$\begin{eqnarray}
\theta = E[\hat{\theta } ]=\int \hat{\theta } p(x|\theta ) dx
\end{eqnarray} $$
両辺\( \theta \)で微分しましょう。
$$\begin{eqnarray}
1 &=& \frac{\partial}{\partial \theta} \int \hat{\theta } p(x|\theta ) dx \\
&=& \int \hat{\theta} \frac{\partial}{\partial \theta} p(x|\theta )dx \\
&=& \int \hat{\theta} \frac{\partial \ln p(x|\theta )}{\partial \theta} p(x|\theta ) dx \\
&=& E[\hat{\theta} L_{\theta}] \\
&=& E[(\hat{\theta} -E[\hat{\theta} ] )(L_{\theta}- E[L_{\theta}])]
\end{eqnarray} $$
最後の量は、共分散と呼ばれています。\( E[\hat{\theta}] E[L_{\theta} =0 \)を足したりしてます。内積の記事で触れた、コーシーシュワルツの公式を使って、共分散から情報を取り出すことが出来ます。

$$\begin{eqnarray}
1 &=& E[(\hat{\theta} -E[\hat{\theta} ] )(L_{\theta}- E[L_{\theta}])] \\
& \leq & \left( V[\hat{\theta}] V[L_{\theta}] \right) ^{1/2} \\
&=& \left( V[\hat{\theta}] I_{N}(\theta ) \right) ^{1/2}
\end{eqnarray} $$
計算してみると、以下の不等式が分かりました。
$$\begin{eqnarray}
V[\hat{\theta} ] \geq \frac{1}{I_N (\theta )}
\end{eqnarray} $$
この式はクラメール・ラオの不等式と呼ばれています。 これは結構凄いことを言っていて、不偏推定量の分散を、Fisher情報量の逆数より小さくは出来ないと言っています。どんなに良い不偏推定量を考えたとしても、分散を0には出来ないのです。
正規分布とポアソン分布の場合でどういうことか見てみましょう。
正規分布について
$$\begin{eqnarray}
I_{N} (\theta) = \begin{pmatrix}
N\lambda & 0 \\
0 & \frac{N}{2\lambda ^2}
\end{pmatrix}
\end{eqnarray} $$
$$\begin{eqnarray}
V[\lambda] & \geq & \frac{2 \lambda ^2} {N} \\
V[\sigma ^2 ] & \geq & \frac{2}{N\sigma ^4} \\
V[\mu] &\geq & \frac{\sigma ^2}{N}\
\end{eqnarray} $$
平均値を推定するときも、分散を推定するときも、母集団のパラメーターより精度よく推定することは出来ないという意味の式が出てきました。一方で、データの数を増やせば、精度を上げる事が出来るとも書いています。機械学習や統計でデータの数が大事と言われる所以です。最尤推定により求めた平均値の推定量が、サンプル数の増加に伴って精度よくなっていくことを見てみましょう。ここで、\( V[\hat{\mu}] =I_{N} (\mu ) \) に注意しましょう。
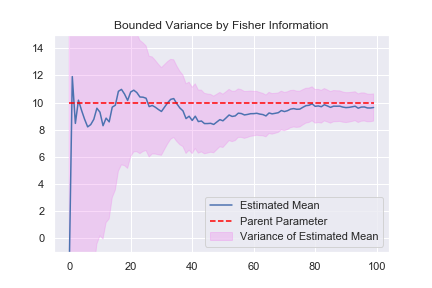
平均値の推定値が段々と真の値に近付くと共に、紫の範囲が小さくなっているのが分かります。これは、データ量が増える事で推定量が精度よく推定できるようになる事を表しています。紫の範囲がFisher情報量の逆数の範囲になっています。
ポアソン分布について
$$\begin{eqnarray}
I_N (\theta) &=& \frac{N}{\lambda ^2} \\
V[\hat{\lambda} ] &\geq &\frac{\lambda ^2 }{N}
\end{eqnarray} $$
ポアソン分布でも最尤推定量の精度が上がっていくか実験してみましょう。
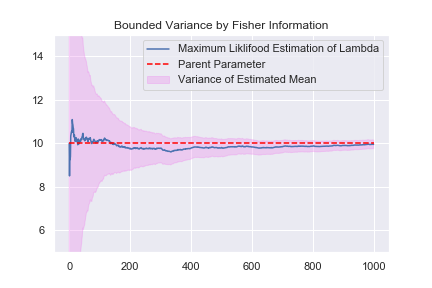
正規分布の時と同じように、分散が小さくなっていく様子を見る事ができました。
まとめ
・最尤法という確率分布のパラメーターを決める手法がある。
・不偏推定量とは、平均を取ると母集団のパラメーターと一致する推定量。
・Fisher 情報量で不偏推定量の分散の下限を知ることが出来る。
・データ数を増やせば、推定の精度を上げる事が出来る。

