
ニューラルネットワークモデルで、畳み込み層を備えたモデルは畳み込みニューラルネットワーク(CNN)と呼ばれていました。再帰層(リカレント層)を備えたモデルはリカレントニューラルネットワーク(RNN)と呼ばれています。この記事では、RNNにおいて代表的なリカレント層の解説をします。
RNNとは?
時間をパラメーターに持つデータは時系列データと呼ばれています。時系列データは\( (h_t , x_t ) \)のように時間でラベル付けされます。時系列データに多く見られる特徴として、自己相関が大きいという事です。つまり、\( h_{t}, h_{t+1} \)は似ているという事です。この特徴を使わないのは勿体ありません。ある時刻のデータに対して予測値を作ったら、その予測値も 特徴量に加えてしまえば、自己相関が大きいという特徴を取り入れたモデルを作る事が出来ます。
時系列データを扱う為に、リカレントニューラルネットワーク(RNN) 1 と呼ばれるモデルが作られました。特徴は、以下のリカレント層で過去の情報を未来のパラメーターに伝える事です。
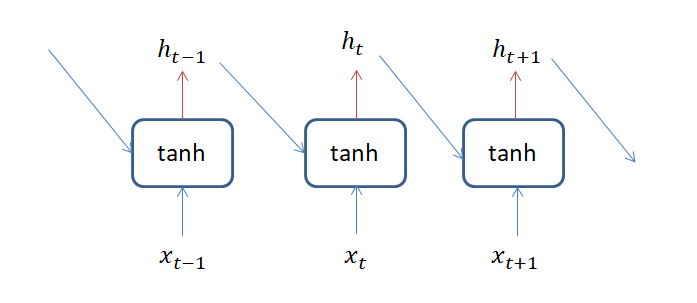
青い矢印部分はニューラルネットワークでいう所の全結合で、赤い矢印は何もせずにデータを流す操作を表しています。\((h_{t-1} , x_t ) \)を\( h_t \)の学習に使い、\({\rm tanh} \) を活性化関数に使っています。時刻\( t\)のデータを予測するのに\( t-1 \)のデータも使って逐一パラメーターを更新することで、昔の情報を未来のパラメーターに伝えています。
上記のモデルで\(t \)が大きくなった時に、過去全ての情報が未来まで届くでしょうか?
答えはNoです。
出力の勾配に関係するのは基本的に行列の掛け算と\({\rm tanh} \)だけなので、行列の特異値によって、勾配消失問題か、勾配爆発問題が起こります。爆発に関しては、許容できる最大値を決めておいて、最大値を超えたら小さくすれば良いのであまり問題にはなりません。しかし、勾配消失は小手先ではどうしようもありません。
このモデルの改良として、LSTM, GRUと呼ばれるモデルが作られました。
RNNからLSTMへ
RNNには、遥か昔の情報を未来に伝える事が出来ないという欠点がありました。それを改良したのが、LSTM(Long Short Term Memory )です。基本はRNNと同じですが、\( {\rm tanh}\)で活性化するだけだった層に工夫を加えています。LSTM層を図にしてみます。
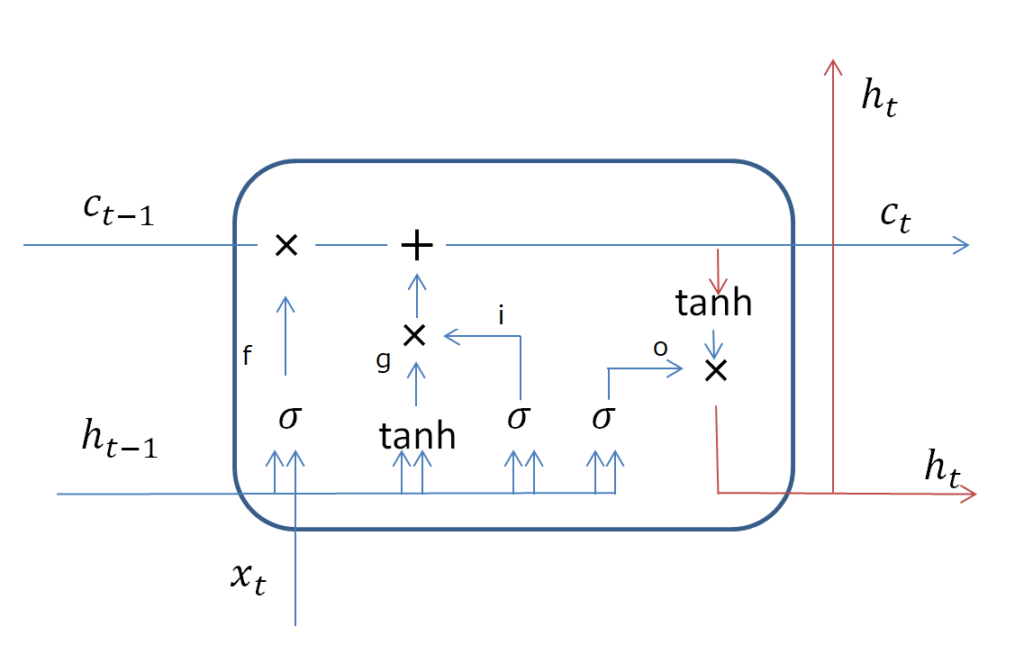
\( \times , +\) は成分毎の積と和で、\(\sigma \)はシグモイド関数 2 です。青線は全結合を表し、赤線は何もせずに流す操作を表しています。
t=t の層での 入力データは\(x_t , h_{t-1} , c_{t-1} \) で、\(c_t, h_{t} \)が出力です。\(h_t \)が予測値です。\(c_t \)は予測値を直接コントロールする量で、セルと呼ばれることが多いです。セルに何か掛けて足して、\({\rm tanh} \)で活性化して予測値という構造になっています。LSTMを理解するには、\( {\rm tanh} , \sigma \)の解釈を考える必要があります。下にシグモイド関数とtanhのグラフを描きます。
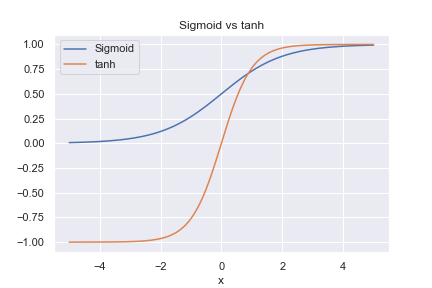
シグモイド関数は0から1までの値を取り。tanhは-1から1までの値を取ります。シグモイド関数はデータを次の層に流す量を決める関数、tanh はデータの情報量の多さ(強さ)を表す関数と考えてみましょう。
LSTMの構造を理解するために、セル\( c_{t-1} \)の情報がどのように書き換えられるかを見ましょう。
初めに、矢印\(f \)で作られた量が\(c_{t-1} \)に掛けられています。\( f\) の部分は、直前の出力 \(h_{t-1} \) と、現在のデータ \( x_t \) から、直前のセルの情報をどの程度忘れる 3 べきかを調節しています。
次に、\( g , i \)で作られた量が \(c_{t-1} \)に足されます。\( f \)で、セルの情報をそぎ落としたので、 \(h_{t-1} , x_t \)から得るべき情報量を選択して加えるのが \(g ,i \) 4 です。
最後に、\( o \)の部分です。(調節された)\(c_{t-1} \)の情報量を測定して、出力とセルへ渡すのが\(o \)の部分 5 の役割です。
RNNでは、勾配消失や勾配の発散が起こり、過去のデータについての情報をあまり記憶できないと書きましたが、LSTMはどうでしょうか。
LSTMでは、出力に関する勾配を考えると、要素ごとの積\(\times \)と、要素ごとの和 + しかありません。+の部分では勾配の変化はありません。\( \times \)の部分は、 \(f \)との積を取る操作になっていたことを思い出しましょう。\( f \)が忘れるべきでないと判断した時点の情報に対しては、勾配が小さくならない 6 ので、過去の情報であるかは関係なく、LSTM層が大事だと判断した情報の勾配は無くならないのです。
GRU
LSTMは計算が重いという欠点があります。それを解消するために登場したのがGRUです。\( t= t\)の層は以下のようになっています。
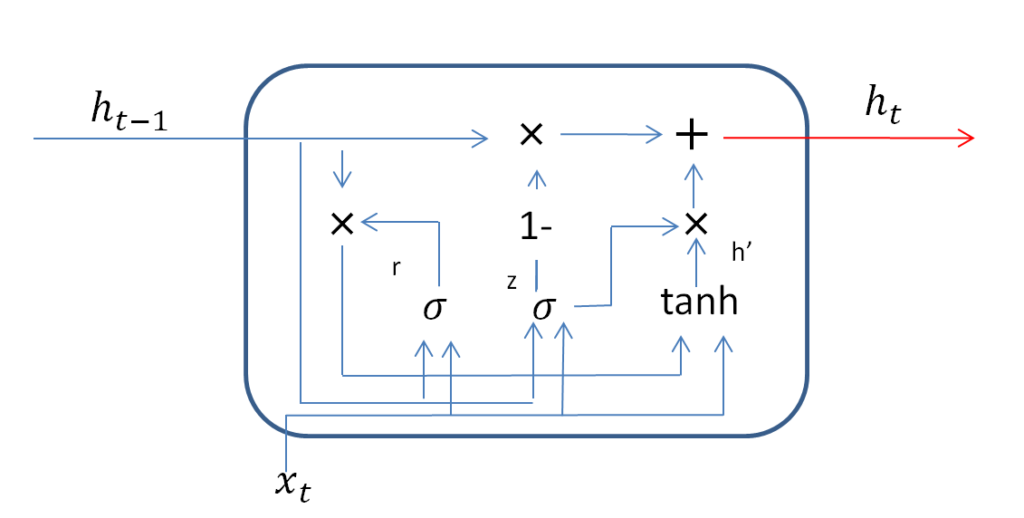
GRU
LSTMの時にあったセルは無くなりました。\(t=t \)の入力は過去の予測値\(h_{t-1} \)と、現在のデータ\( x_t \)です。LSTMでは忘れるべき情報をコントロールする部分と得るべき情報をコントロールする部分がバラバラでしたが、GRUでは一つになります。それが\(z\) の部分で、計算すると
$$\begin{eqnarray}
( 1-z )\times h_{t-1} +z\times h’
\end{eqnarray}$$
となります。 \(1-z \times h_{t-1} \)が忘れるべき情報を制御し、\( z \times h’ \)が得るべき情報をコントロールしてくれる 7 と考えます。
LSTMと同様、予測値の勾配に関係するのは\( +, \times \)なので、勾配消失は起こしにくいと考えられます。
RNN vs LSTN vs GRU
RNNは、時系列データだけでなく、自然言語処理の世界でも注目されています。例えば、以下の文章の最後に当てはまる言葉を予測してみてください。
I am Masamune. I am from Japan. So I fluently speak —.
答えはJapanese です。
答える為には、speak という単語は言葉に関係しているという事、I = マサムネであること。マサムネは日本に住んでいたという事を理解する必要があります。
speak からどんどん昔の単語に戻っていって答えの情報を探さなくてはなりません。昔(以前に登場した単語)の情報が役に立つという意味で、時系列データと自然言語は似ているのです。
そこで、映画レビューを見て、良い感触を持ったか否かをRNN, GRU, LSTMで当ててみます。
使うデータセットはkeras のimdb データセットです。
以下にモデルの学習の最後の方を載せます。
#RNN
Epoch 9/10
25000/25000 [==============================] - 119s 5ms/step - loss: 0.5253 - acc: 0.7243 - val_loss: 0.6309 - val_acc: 0.6705
Epoch 10/10
25000/25000 [==============================] - 118s 5ms/step - loss: 0.4521 - acc: 0.7919 - val_loss: 0.6206 - val_acc: 0.6930
#LSTM
Epoch 9/10
25000/25000 [==============================] - 644s 26ms/step - loss: 0.1004 - acc: 0.9633 - val_loss: 0.3903 - val_acc: 0.8788
Epoch 10/10
25000/25000 [==============================] - 644s 26ms/step - loss: 0.0810 - acc: 0.9721 - val_loss: 0.4109 - val_acc: 0.8780
#GRU
Epoch 9/10
25000/25000 [==============================] - 384s 15ms/step - loss: 0.0356 - acc: 0.9884 - val_loss: 0.6356 - val_acc: 0.8680
Epoch 10/10
25000/25000 [==============================] - 382s 15ms/step - loss: 0.0231 - acc: 0.9924 - val_loss: 0.6561 - val_acc: 0.8696Google colab でGPUを使用して計算しました。注目したいのはval_acc と学習にかかっている時間です。RNNは最も学習速度が速いですが、正答率は最も悪くなっています。LSTMとGRUの正答率はどっこいどっこいですが、学習にかかる時間は倍くらい違って 8 います。
まとめ
- ニューラルネットワークの一種にRNNがある
- RNNの改良版としてLSTM, GRUがある
- LSTMは計算に時間がかかる
- GRUはLSTMと比べて計算は軽いが、RNNと比べれば重い

