
機械学習やベイズ統計で使われる、生成モデル(generative model )を紹介します。一昔前に 敵対的生成 ネットワーク,GAN(Generative Adversarial Networks)が話題になりましたが、それと同じ系譜です。顔や動物、萌え絵の生成が有名ですね。
オライリーで本が無料で公開されていたので、それを参考に書いています。モデルもgithub に置いてあるので、読んでみるのをお勧めします。
https://www.oreilly.com/library/view/generative-deep-learning/9781492041931/
https://github.com/davidADSP/GDL_code
この記事の中では、基本的なニューラルネットワークの層は知っていると思っています。例えば、畳み込み層とか全結合層とかです。知らない人は、ググるか以下の記事を読んでみてください。


筆者のgithubを見るのが一番だと思いますが、一応コードとトレーニング済みのモデルをgithub に置いておきます。
生成モデルとは
生成モデルとは、扱うデータがどのように生成されているかを学習するモデルです。
学習が終わると、扱うデータと似たようなデータを新たに作ることが出来ます。
大体の原理を説明します。
generative modelは、Encoder と呼ばれるモデルとDecoder と呼ばれるモデルの2つから成っています。Encoder の出力とDecoder の入力は同じ次元で、潜在空間(latent space)1と呼ばれています。また、Encoder の入力とDecoder の出力は同じ次元を持っています。Encoder の入力と、Decoder の出力が一致するように、モデルを学習させます。
イメージ的には、元のデータの情報をEncoderで潜在空間に落とし込み, Decoder で潜在空間の点をデータに復元する、という感じです。一般的には、潜在空間は、Encoder からデータが貯められるだけで、位相的な、点同士が近いとか遠いとかの情報が役に立たない空間になっています。
Encoder は、主成分分析でデータを小さな次元にまとめるようなイメージです。主成分分析では、主成分の空間からデータを復元する事は出来ませんが、generative model ではそれが可能になっています。
最も簡単な例は、手書き文字からなるデータセット(mnist)を学習して、それっぽい絵を描くことです。
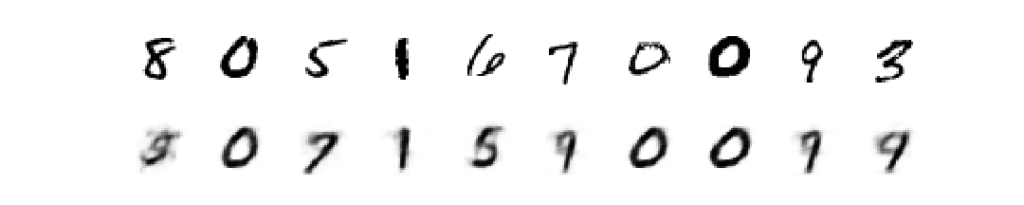
上の画像がテスト用のデータで、下側がそのデータを再現しようとしてモデルが出力した画像です。下の画像がかすれているように見えるのは、使用したモデルの特性によるものです。2
生成モデル(generative model)と識別モデル(discriminative model)
生成モデルの目的を理解するために、識別モデルとの対比を考えるのが定番のようです。この対比は、混合正規分布によってデータから確率分布を決定してデータを生成する場合と、ラベルを当てる為に機械学習モデルを作る状況が良く似ています。データを\(x\) ラベルを\(y\)で表し、確率分布を\(p(-) \)で表しましょう。
ラベルを当てる機械学習モデル(識別モデル)は、確率分布\(p(y|x) \)を作るのが目的です。データ\(x\)を与える事で、ラベル\(y\)が求められるモデルです。
一方、混合正規分布(生成モデル)は\(p(x)\)を作るのが目的です。混合正規分布が出来てしまえば、\(p(x|y) \)から、あるラベルを表すようなデータをサンプルすることも出来ます。
識別モデルを使いたい場合は、\(y\)は\(x\)から決まるという事が仮定されています。そして、確率分布\(p(y|x) \)を決めるのが目的です。
一方、生成モデルの場合は、ラベルと\(x\)の関係は全く気にしません。得られたデータ全てについて確率分布を予測します。そのため、\( p(x) \)を決めて、\(p(x|y ) \)を求める、という事も行います。
モデルの目的が違う事に注意しましょう。
pythonで生成モデルを使ってみる
オライリーの本に載っているモデルを使って、少し遊んでみます。mnistのデータを使います。
生成モデルの特徴は、Encoder を学習させることによって、潜在空間でデータがどのように分布しているか見られる事です。使うEncoder, Decoder は次のようになっています。3


グラフにしやすいように、潜在空間は2次元としています。また、誤差関数は、Encoder の入力とDecoder の出力で、平均二乗誤差を考えます。4
Encoder を学習して潜在空間を描画し、ラベルで色分けすると以下のようになります。
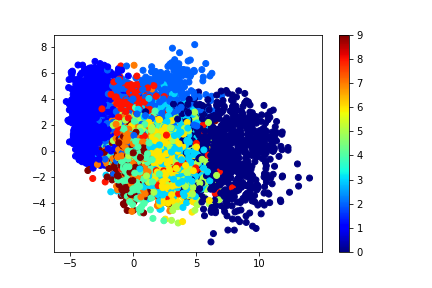
分類問題を解いた結果のグラフだと思うと、あまり上手くいっていないように感じると思います。何故なら、一塊の中に全ての数字が混在しているような状態だからです。これは、潜在空間がデータの入れ物としか機能していない為に起こっています。
潜在空間に少し手を加える事で、上手く分類できているようなグラフを描くことが出来ます。
具体的には、潜在空間に描画される点が(多次元)正規分布に従うようにするのです。5
その為に、Encoder の出力を\(\mu , \sigma \)の2種類用意します。そして、正規分布\( \mathcal{N} (\mu, \sigma ^2) \)と標準正規分布とのKLダイバージェンスを考えます。6
$$\begin{eqnarray}
E_1 =KL[ \mathcal{N} (\mu, \sigma ^2) \| \mathcal{N}(0, I) ]
\end{eqnarray}$$
誤差関数に\(E_1 \)を加えてモデル全体を学習することで、潜在空間に制限を掛ける事が出来ます。また、学習後のEncoder の出力\(\mu , \sigma \)を使い、潜在空間の点を正規分布 \( \mathcal{N} (\mu, \sigma ^2) \) からサンプリングする事で表現できます。Encoder は以下のようなモデルになります。
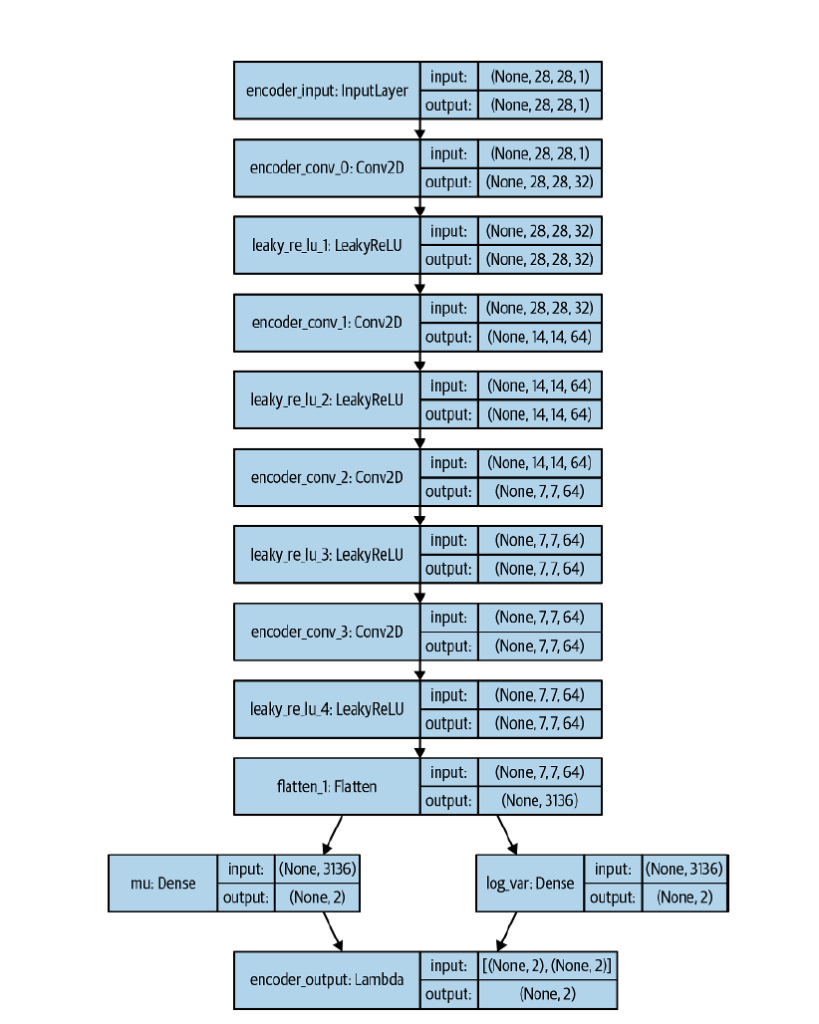
Lambda 層は、\(\mu , \sigma \)から正規分布の点をサンプルする層です。
VAEモデルを学習すると、7潜在空間(正規分布)でのラベルの分布と、対応する点の累積積分値のラベルの分布は以下のようになります。
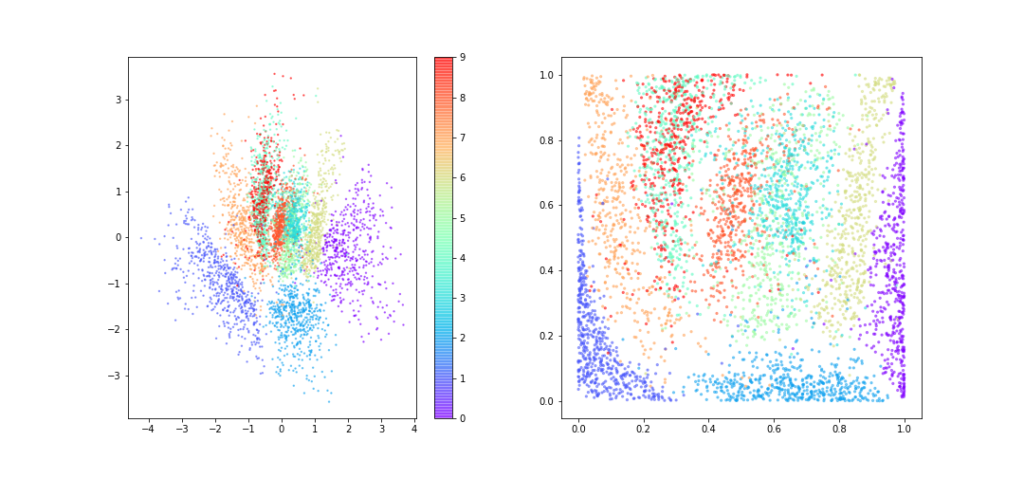
AEモデルよりも分類は上手くいっているように見えます。
それぞれのモデルでテスト用のデータを描画してみましょう。

VAEモデルの方がくっきりと文字を描けています。また、VAEモデルの方が、AEモデルよりうまく特徴を学習しているように見えます。
AEモデルとVAEモデルでは、潜在空間に違いがありました。それを最後に確認します。
VAEモデルで、潜在空間の適当な点をDecoder に通して新たに数字を描いてみましょう。これが出来るのが、生成モデルと呼ばれる所以です。
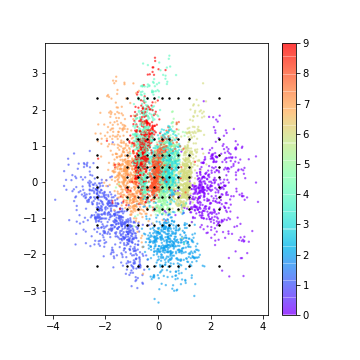

潜在空間の近い点では、同じような絵を描いてほしい訳ですが、VAEモデルでは近い点同士では同じような絵を描いてくれています。
同じことをAEモデルでもやってみましょう。
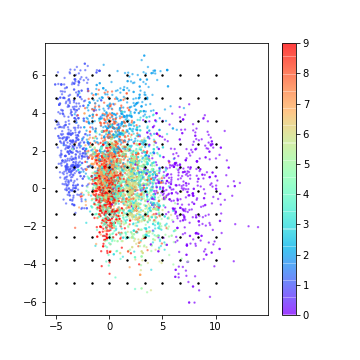

VAEモデルと比べて、画像の変化が滑らかでないように見えます。つまり、右側の”0″が急に違う数字に変わっています。
また、左上の画像は数字として判別できません。8なぜ、VAEモデルとAEモデルでこんなにも差があるのでしょうか。
答えは、AEモデルの潜在空間が必ずしも連続的な空間とは限らないからです。Encoder からの出力としては連続ですが、出力が近いという事と、データが似ているという事は要請されていないのです。9
一方で、VAEでは、KLダイバージェンスを誤差関数に含める事で、潜在空間が確率分布からサンプリング出来るように要請されています。これによって、潜在空間で近い点はDecoder の出力が似てい事が担保されています。
まとめ
- 生成モデルのを大まかに説明した
- 生成モデルと識別モデルの違いを説明した
- AEモデルとVAEモデルを使ってみた
- 潜在空間に制約を加える事で、良いモデルが作れる事を説明した
- データの情報を保管しておく空間です。
- AEモデルを使ってます。
- AE(AutoEncoder)モデルと呼びます。
- Encoder とDecoder で入力や出力の次元が一致していることを確認してください。
- VAE(Variational AutoEncoder )モデルと呼びます。
- KL ダイバージェンスについては、解説記事があります。
- VAEは学習に時間がかかるので、管理人のgithub に置いてあるvae_trained.h5 を使うと良いかもしれません。
- ラベルは1か2っぽいですが。
- 識別モデルだとこのような事は起こりませんね。

