
機械学習において必ず直面する問題があります。 それは、データ不足、特徴量の不足、そして過学習 です。 1 過学習が起きる理由の一つに、モデルの汎化性能が低い、という事が挙げられます。汎化性能について説明し、どうすればモデルの汎化性能を上げる事が出来るか、過学習を防げるか解説します。
汎化性能とは
与えられた訓練データを再現する力の事を表現力と呼びます。使うモデルの表現力が高すぎると、データの些細な挙動までモデルが学習してしまい、未知のデータの予測が難しくなります。2
データに含まれる誤差の部分を無視する力を汎化性能と呼びます。汎化性能が大きすぎると、データの構造の大事な部分も無視してしまい、鈍感なモデルとなります。3
モデル選択による汎化性能の向上
使用するモデルが違うだけで、汎化性能に差があります。それを確かめる為に、 色々なモデルにデータを与えて、どのくらい正確に表現出来るかを考える事で、表現力の高さを比べてみます。次に、未知のデータを予測させることで、汎化性能を比べます。
サインカーブ+直線+誤差の形のデータを学習、予測させます。
比較に使うモデルは、回帰、カーネル回帰、カーネルリッジ回帰です。4モデルは以下の式でパラメーター\( w , \alpha \)を推定する事で作られます。
$$\begin{eqnarray}
y&=& \vec{w} \cdot \vec{x} \\
y&=& \sum K_{ij} \alpha _{j} \\
y&=& \sum K_{ij} \alpha _{j} +\lambda \alpha ^T K \alpha
\end{eqnarray}$$
これらのモデルは、使う誤差関数によってはサポートベクトルマシンになります。対応は以下の表の通りです。

回帰分析とカーネル回帰、カーネルリッジ回帰の表現力を比べます。
コードと結果を載せます。
import numpy as np
import matplotlib.pyplot as plt #グラフの為のライブラリ
import seaborn as sns #グラフの為のライブラリ
from sklearn.svm import SVR #SVR使用のためのライブラリ
from sklearn.kernel_ridge import KernelRidge #カーネルリッジ使用のためのライブラリ
sns.set() #グラフを綺麗にするおまじない
n=50 #表現力を見るためのデータ作成
a=np.random.normal(loc = 0, scale = 0.21,size = n)
x=np.linspace(-3,3, n).reshape(-1,1)
pix = np.pi * x
y=a+np.sin(pix)/pix + 0.5 *x + a
clf = KernelRidge(alpha=0, kernel='rbf') #カーネル回帰
clf.fit(x, y)
p = clf.predict(x)
clf_L2 = KernelRidge(alpha=0.3, kernel='rbf') #カーネルリッジ回帰
clf_L2.fit(x, y)
p_L2 = clf_L2.predict(x)
plt.scatter(x, y) #グラフを描くためのコード
sns.regplot(x=x,y=y, order=1, scatter=False,label="Linear")
plt.plot(x, p, label ="Kernel")
plt.plot(x, p_L2, label ="Kernel Ridge")
plt.legend()
plt.title("Linear vs Kernel vs Kernel Ridge")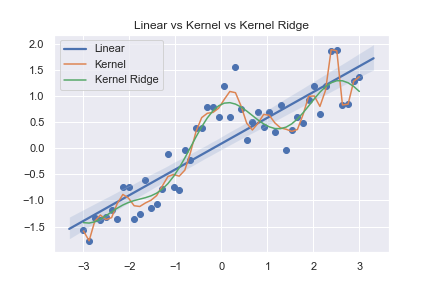
全てのデータを説明するという点では、カーネル回帰が一番優れています。表現力はカーネル回帰が一番高いです。 5
このデータから得られたパラメーターを元に、未知データを予測させてみます。未知データを綺麗に予測できるのが、汎化性能が高いという事だったことを思い出しましょう。
コードと結果を載せます。
N=100 #汎化性能を見るためのデータ作成
A=np.array(np.random.normal(loc = 0, scale = 0.21, size = N)).reshape(-1,1)
X=np.linspace(-3,3, N).reshape(-1,1)
piX=np.pi * X
Y=np.sin(piX)/piX + 0.5 *X + A
clf = KernelRidge(alpha=0, kernel='rbf') #カーネル回帰のモデル生成
clf.fit(x, y)
p =clf.predict(X) #モデルに基づく予測
clf_L2 = KernelRidge(alpha=0.3, kernel='rbf') #カーネルリッジ回帰のモデル生成
clf_L2.fit(x, y)
p_L2 = clf_L2.predict(X) #モデルに基づく予測
lr = LinearRegression().fit(x,y) #線形回帰
p_lr = lr.predict(X)
plt.scatter(X, Y, marker=".") #データのプロット
plt.plot(X, p_lr, label ="Linear")
plt.plot(X,p, label="Kernel")
plt.plot(X, p_L2, label ="Kernel Ridge")
plt.legend()
plt.title("Linear vs Kernel vs Kernel Ridge")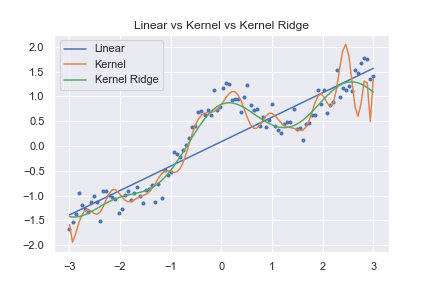
グラフを見て分かるように、汎化性能が一番良いのはカーネルリッジ回帰でした。
与えられたデータを表現するという点ではカーネル回帰が圧勝でしたが、未知のデータを予測させようと思うと、カーネル回帰は役に立ちそうもありません。現実で今のデータを予測するならカーネル回帰よりも直線でフィットした方がマシかもしれません。
カーネルリッジ回帰は与えられたデータでも未知のデータでも同じような曲線を返しています。これが、汎化性能が高い、という事です。
基本的にパラメーターが多ければ多い程表現力が高く、過学習しやすいです。
一般に、モデルにペナルティ項が付いていると、汎化性能が大きくなります。
誤差関数の違いによる汎化性能の違い
モデルは同じでも、誤差関数を変えると別のモデルになることがあります。誤差関数を変えるという事は、モデルがどのようにデータを学習するかが変わってきます。
例えば、カーネルリッジ回帰で、平均2乗誤差をε不感応誤差に変えると、サポートベクトル回帰になります。6
誤差関数の違いで、汎化性能に差が出るのか調べてみましょう。
データとして、以下の関数から適当に点をサンプルします。
$$\begin{eqnarray}
y=x\sin x + \mathcal{N}(x|1,0.5)
\end{eqnarray}$$
ただし、\( \mathcal{N}(x|1,0.5) \)は、平均1、分散0.5の正規分布を表しています。
このデータを使って、カーネルリッジ回帰とサポートベクトル回帰の汎化性能や表現力を比べます。
コードと実行結果を載せます。
n=100 #表現力を見るためのデータ作成
a=np.array(np.random.normal(loc = 1, scale = 0.5, size = n )).reshape(-1,1)
x=np.linspace(-3,3, n).reshape(-1,1)
pix = np.pi * x
y=x*np.sin(pix) +a
svr =SVR(kernel="rbf").fit(x,y)#サポートベクトル回帰のモデル作成
p_sv = svr.predict(x)
clf_L2 = KernelRidge( kernel='rbf')
clf_L2.fit(x, y)
p_L2 = clf_L2.predict(x)
plt.scatter(x, y, marker="." )#グラフ描画
plt.plot(x, p_L2, label ="Kernel Ridge")
plt.plot(x,p_sv, label="Support Vector")
plt.legend()
plt.title("Squared Error vs ε Insensitive Error")
plt.show()
N=1000 #汎化性能を見るためのデータ作成
A=np.array(np.random.normal(loc = 1, scale = 0.5, size = N)) .reshape(-1,1)
X=np.linspace(-3,3, N).reshape(-1,1)
piX=np.pi * X
Y=np.sin(piX)/piX + A
Y_tr =X* np.sin(piX) +1
svr =SVR(kernel="rbf").fit(x,y) #サポートベクトル回帰のモデル作成
p_sv = svr.predict(X)
clf_L2 = KernelRidge( kernel='rbf')
clf_L2.fit(x, y)
p_L2 = clf_L2.predict(X)
plt.scatter(X, Y, marker=".", color="white", ) #グラフ描画
plt.plot(X, Y_tr, label ="Sin Curve" , color ="y")
plt.plot(X, p_L2, label ="Kernel Ridge")
plt.plot(X,p_sv, label="Support Vector")
plt.legend()
plt.title("Squared Error vs ε Insensitive Error")
plt.show()
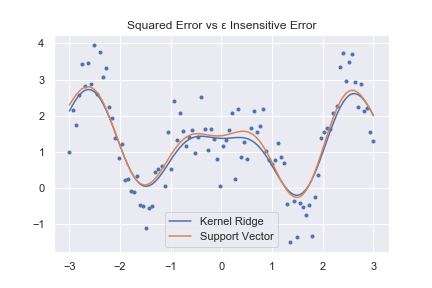
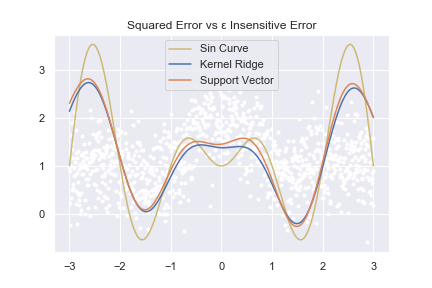
左側が関数の再元で、右側が関数の予測です。予測の場合は背景に出ている白い点がデータを表しています。また、黄色い線で\( x\sin (x) \)のグラフを描いています。
どちらのグラフを見てもカーネルリッジ回帰とサポートベクトル回帰は同じような結果を返しています。
汎化性能や表現力という点では、誤差関数の選択はあまり関係が無い事が分かります。
このグラフで大事なのは、\( x\sin (x) \)(薄黄色の線)と比べるとモデルの予測は凸凹が小さく出ている点です。
どちらのモデルも、ノイズらしきものを無視しすぎて元の関数が持っている本来の構造を上手く捉える事が出来ていません。これが汎化性能が高すぎて、表現力が小さい状態です。
この状態は、誤差項\( \lambda \alpha ^{T} K \alpha \)のペナルティ\(\lambda \)を弄ることで様子が変わってきます。\( \lambda \)を変えてグラフを描いてみましょう。
コードと結果を載せます。
I = [0.001, 0.1, 1,10] #λに代入したい数字
for i in I:
clf_L2 = KernelRidge( kernel='rbf', alpha= i)
clf_L2.fit(x, y)
p_L2 = clf_L2.predict(X)
plt.plot(X,p_L2 , label = "λ= {}".format(i) ,lw=1 )
plt.plot(X, Y_tr,"--", label="sin curve", color="black" )
plt.title("Effect Of Penalty Term")
plt.legend() 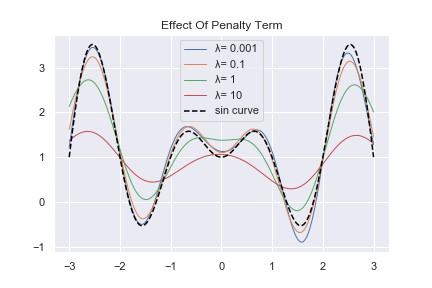
\( \lambda \)が大きければ大きい程予測値のグラフが寝ているのが分かります。ペナルティ項を大きくし、汎化性能を大きくするのは、予測値の凹凸を少なくする効果があります。
汎化性能が高いと、鈍感なモデルになると初めに書いたのは、こういうわけです。
汎化性能を高めるには
カーネル回帰は、元来表現力がとても高い柔軟なモデルであるが故に、敢えてモデルを鈍くしないと、過学習を起こしてしまいます。しかし、鈍くしすぎると鈍感になりすぎてしまい、使い物にならなくなります。つまり、表現力と汎化性能はトレードオフの関係にあります。
これは機械学習全般でいえる事です。基本的に。与える訓練データに対して、モデルは十分すぎ津表現力を持っています。使うモデルを丁度良く邪魔する項を取り入れる事で、結果的に良いモデルにしています。
つまり、汎化性能を高めるには、モデルに誤差項に当たるものを取り入れれば良いです。
例えば、ニューラルネットワーク由来のモデルでは、ドロップアウトやバッチノーマリゼーションなどがそれにあたります。
まとめ
- パラメーターの数が多くなると、表現力が大きくなる分過学習しやすくなる。
- 誤差項の違いによってモデルの呼び名が変わる。
- 普段使うモデルは、表現力が非常に高く、そのままだと過学習を起こす。
- ペナルティの導入によって、あえて表現力を落とすことが出来る。
- ペナルティ項を強くしすぎるとモデルが役に立たなくなる。
- 過学習というのは、データの大事な構造だけでなくて、誤差の部分も学習してしまう事です。
- 過学習と呼ばれる状態です。
- この記事では、python を使って色々なモデルを考えます。pythonを使う環境が無い人はGoogle Colabを使ってみることをお勧めします。
- カーネル法については、入門記事をどうぞ。
- 過学習しやすいともいえます。
- サポートベクトルマシンの記事があるので詳細が気になる人はどうぞ

