
機械学習において、誤差関数の勾配には非常に大きな価値があります。
モデルの学習の最中に、誤差関数の勾配が0になってしまう問題を、勾配消失問題と呼びます。逆に、勾配が発散してしまう問題を勾配爆発問題と呼びます。
それぞれの問題が起こる状況を再現してみます。勾配爆発問題は簡単に対処可能なので、その対処法を解説します。
勾配消失問題
活性化関数にシグモイド関数 を使うニューラルネットワークモデルを考えます。勾配消失が発生して、入力に一番近い層のパラメーターが更新されなくなる事を実験したいと思います。
ニューラルネットワークの入門記事は以下を読んでみてください。

シグモイド関数は以下で定義される関数でした。
$$ \begin{eqnarray}
\sigma (x) =\frac{1}{1+\exp (-x)}
\end{eqnarray}$$
グラフは次のようになります。
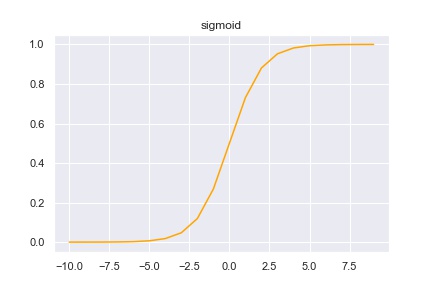
0から1まで、滑らかに大きくなる微分可能な関数です。どんなに大きな値が入ってきても、シグモイド関数は0以上1以下の値を返します。シグモイド関数の微分は次の式で表されます
[mathjax]$$ \begin{eqnarray}
\sigma ^{,}(x) = \sigma (x)(1- \sigma (x))
\end{eqnarray} $$
式を見ても1未満の関数であることが分かりますが、グラフは以下のようになっています。
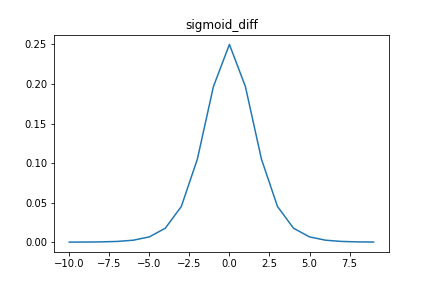
シグモイド関数の微分は、0以上0.25以下の値を取ります。勾配法では、誤差関数の勾配\( \nabla L \)と、学習率と呼ばれるハイパーパラメーター\(\eta \) で、でモデルのパラメーターを更新していました。
$$\begin{eqnarray}
\alpha ^{,} =\alpha -\eta \nabla L
\end{eqnarray}$$
また、とある層\(A\)のパラメーター更新には、\(A \)より出力側の勾配が全て影響してきます。1
誤差関数に近い層ではあまり影響が無いかもしれませんが、出力層側では活性化関数を通過するたびに1未満の数が乗じられることになり、パラメーターの更新幅が小さくります。
以下のようなモデルで、タイタニック号の生存者の予測をしてみます。ニューラルネットワークモデルの1層目の前に同じような層を付け加えました。Eは誤差関数を表しています。誤差関数はクロスエントロピー誤差を使用します。
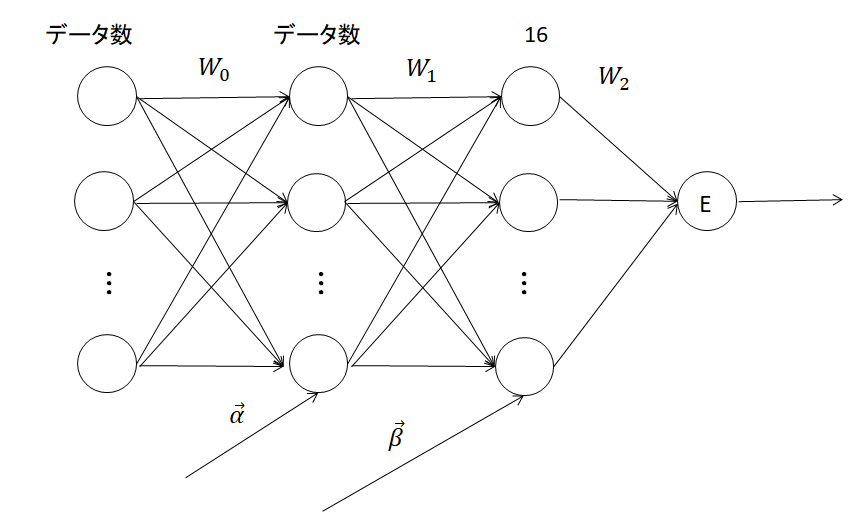
パラメーター\( W_0 , W_1 , W_2 \)に注目してみます。 それぞれの行列の次元は、\( W_0 \)がデータ数×データ数 , \( W_1 \)が16×データ数 , [mathjax]\( W_2 \)が16×1 です。
パラメーターが行列なので、勾配も行列で出てきます。\( L^2\)ノルムを使って勾配の大きさを評価しましょう。ベクトルや行列の[mathjax]\(L^2\) ノルムは以下の式で定義されます。
$$\begin{eqnarray}
\| X \|_{L^2} =\sum_{i,j} x_{ij} ^2
\end{eqnarray}$$
50回パラメーターの更新を行います。勾配はL2ノルムで評価し、パラメーターは行列の要素を一つ決めて、どのように更新されていくか調べます。
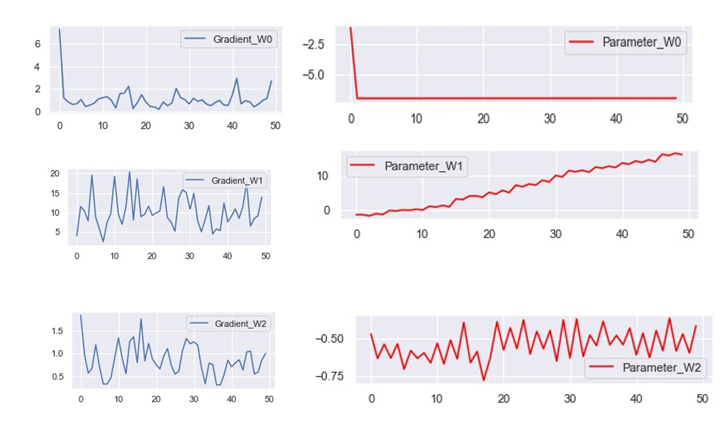
\( W_0\) が10回の更新を待たない間にほぼ定数になっています。一度落ち着いてからは、殆ど変化がありません。勾配には変化がありますが、パラメーター自体の動きは殆ど無くなっています。しかし、[mathjax]\( W_0 \) と[mathjax]\( W_2 \) の勾配の大きさを比べると、大きな違いはありません。パラメーターの大きさに差があるため、[mathjax]\( W_0 \)の方だけ更新が止まっているように見えています。
\(W_1\) は、パラメーターが更新され続けているので、2層までのニューラルネットワークなら、シグモイド関数を使っても良さそうです。
ニューラルネットワークモデルで勾配消失問題が起こる原因は、シグモイド関数の微分が1未満という事でした。これを解決するために、ReLU関数が一般的に使われています。
$$ \begin{eqnarray}
ReLU(x) =\max (x.0)
\end{eqnarray} $$
この関数の微分は、0以上で1, 0未満では0となっているので、勾配消失を起こす可能性が低いと言えます。活性化関数にsigmoid関数とrelu関数を使ったモデルで、どんな違いが出るか比べてみましょう。
記事で使っているソースコードはgithub に置いてあります。
https://github.com/msamunetogetoge
データはfashon mnist を使います。モデルは自作の適当なやつです。
入力→3層全結合→バッチノーマリゼーション→3層全結合→ドロップアウト→出力
です。活性化関数は全てシグモイド関数か、relu です。
#活性化関数でsigmoidを使うモデル
model_relu = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(32, activation='relu'),
keras.layers.BatchNormalization(),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dropout(0.25),
keras.layers.Dense(10, activation='softmax')
])
#活性化関数でreluを使うモデル
model_sigmoid = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(32, activation='sigmoid'),
keras.layers.Dense(32, activation='sigmoid'),
keras.layers.Dense(32, activation='sigmoid'),
keras.layers.BatchNormalization(),
keras.layers.Dense(32, activation='sigmoid'),
keras.layers.Dense(32, activation='sigmoid'),
keras.layers.Dense(32, activation='sigmoid'),
keras.layers.Dropout(0.25),
keras.layers.Dense(10, activation='softmax')損失関数の値を比べます。
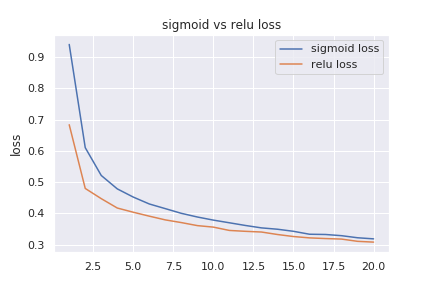
training loss 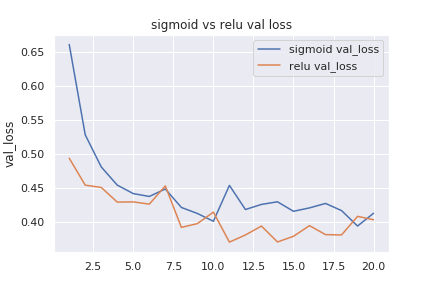
validation loss
training もvalidation もrelu を使ったモデルの方が小さい値になっています。
次に、重みがどのように更新されているか比べます。tensorflow に付属しているtensorboard を使います。
tensorboard では、バイアスベクトルと重みの値の分布を表示することが出来ます。2画像奥側が1エポック目で、画像手前が最終エポックを表します。横軸が重みなどの値で、縦軸は度数です。
reluを活性化関数に使った場合とsigmoidを使った場合の入力側、出力側の分布を見てみましょう。
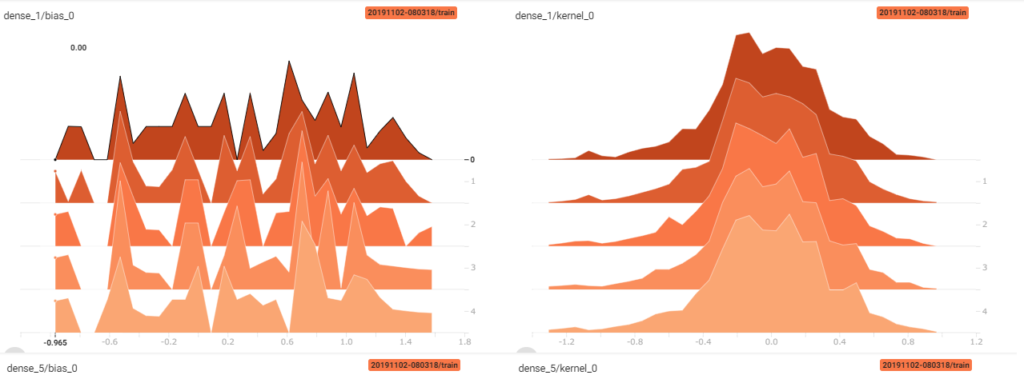
relu入力側 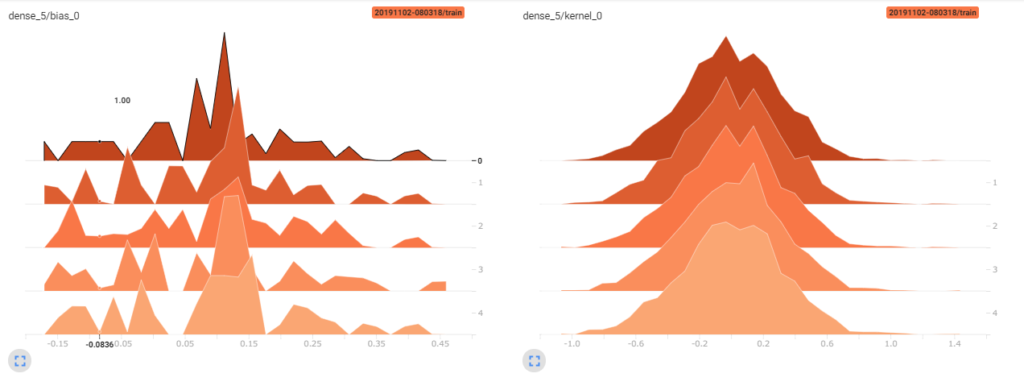
relu出力側
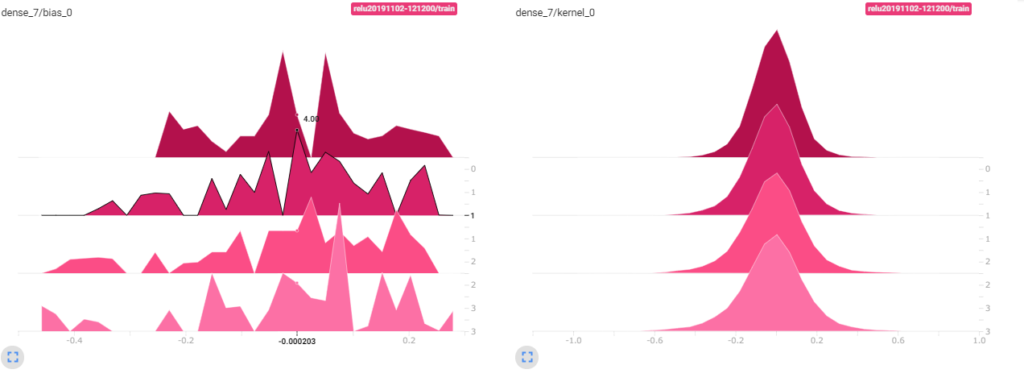
sigmoid入力側 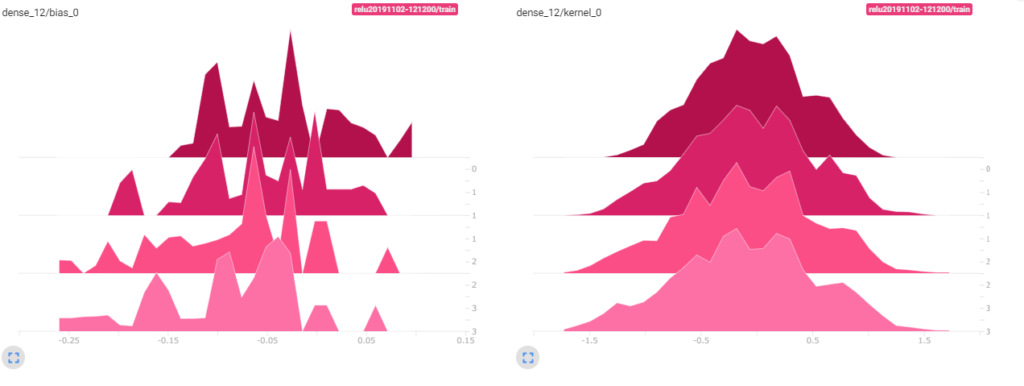
sigmoid出力側
reluもsigmoidもバイアスは良い感じにばらけています。
カーネル(重み行列)の部分では、出力側は殆ど同じ形をしていますが、入力側は値の幅が全然違う結果になっています。画像の奥から手前にかけて分布が鋭いまま形が変わっていないのは、勾配が殆ど更新されていないことを示しています。
勾配発散問題
勾配発散問題は、勾配が大きくなりすぎて、コンピューターが処理できなくなる問題です。勾配発散問題は、案外簡単に起こります。行列の積が絡むモデルでは簡単に起こったりします。例えば、シンプルなRNNでさえ起こります。
RNNについての記事は以下をどうぞ。
RNNでは、決まった時間サイズ分だけ、行列の積と活性化関数が繰り返されるという特徴があります。活性化関数は恒等関数( \( id(x) =x ) \) だとすると、時間サイズの分だけ行列の積が繰り返されることになります。行列の積の微分は、掛けられる側の行列の転置であり、行列のノルムは特異値で決まるので、簡単に勾配爆発が起きてしまいます。
時間サイズを20として計算させてみます。
import numpy as np
import matplotlib.pyplot as plt
N = 2 # ミニバッチサイズ
H = 2 # 隠れ状態ベクトルの次元数
T = 20 # 時系列データの長さ
h = np.ones((N, H))
np.random.seed(3)
Wh = np.random.randn(H, H)
norm_list = []
for t in range(T):
dh = np.dot(dh, Wh.T)
norm = np.sqrt(np.sum(dh**2)) / N
norm_list.append(norm)
# グラフの描画
plt.plot(np.arange(len(norm_list)), norm_list)
plt.xticks([0, 4, 9, 14, 19], [1, 5, 10, 15, 20])
plt.xlabel('time step')
plt.ylabel('norm')
plt.title("Gradient Divergence")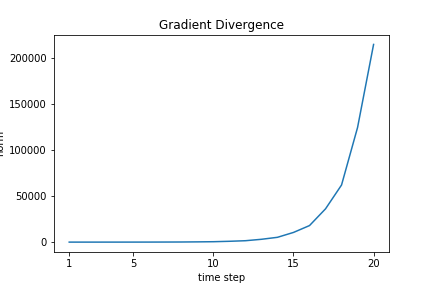
グラフを見ると、勾配がどんどん大きくなっていることが分かります。勾配爆発の対処は簡単です。以下のコードのように、勾配の上限値を決めて、上限値以上になったら上限値で正規化してしまえばいいのです。
式で描くと以下のようになります。上限値を\(M \)で表し、勾配を\(g \)で表します。
$$\begin{eqnarray}
g = \frac{M}{\| g\|} g
\end{eqnarray}$$
この操作をクリッピングと呼びます。実装して試してみましょう。
def clip_grads(grads, max_norm): #クリッピング
total_norm = 0
for grad in grads:
total_norm += np.sum(grad ** 2)
total_norm = np.sqrt(total_norm)
rate = max_norm / (total_norm + 1e-6)
if rate < 1:
for grad in grads:
grad *= rate
dh = np.ones((N, H))
np.random.seed(3)
Wh = np.random.randn(H, H)
norm_list = []
for t in range(T):
dh = np.dot(dh, Wh.T)
clip_grads(dh, max_norm=100)
norm = np.sqrt(np.sum(dh**2)) / N
norm_list.append(norm)
# グラフの描画
plt.plot(np.arange(len(norm_list)), norm_list)
plt.xticks([0, 4, 9, 14, 19], [1, 5, 10, 15, 20])
plt.xlabel('time step')
plt.ylabel('norm')
plt.title("Gradient Clipping")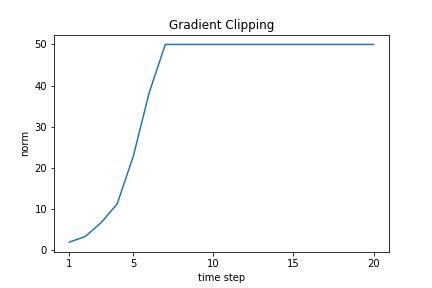
勾配の大きさが制限されることで、上限よりは大きくなっていないことが分かります。このように、勾配爆発は簡単に対処することが出来ます。
まとめ
- ニューラルネットワークで、活性化関数にシグモイドを使うと、勾配消失が起きる。
- ReLU関数を使う事で、勾配消失を防げることがある。
- 行列の積を繰り返すと、勾配爆発が起きる
- 勾配爆発には、クリッピングで対処できる。

