
サポートベクトルマシンは、分類問題に使われる事が多いモデルです。
分類に使う時は、SVC、回帰に使う時はサポートベクトル回帰(SVR)と呼びます。サポートベクトル回帰の原理を解説します。
サポートベクトル回帰は、原理的に過学習しにくいようモデルです。サポートベクトルマシンの復習はこちらからどうぞ。

カーネル法の復習はこちらからどうぞ。
サポートベクトル回帰
サポートベクトル回帰のモデルはサポートベクトルマシンと同じで、以下の式です。
$$\begin{eqnarray}
f( \vec{x} )= K \vec{\alpha}
\end{eqnarray}$$
ただし、Kはカーネルです。このモデルの2乗誤差を考えると、カーネル回帰になりますが、次の誤差関数を使うと、サポートベクトル回帰になります。\( z= y – f( \vec{x} ) \)と置きます。
$$\begin{eqnarray}
r_{\epsilon} (z) = \begin{cases}
-z-\epsilon & (z< – \epsilon )\\
z & (- \epsilon \leq z < \epsilon )\\
z- \epsilon & ( z \geq \epsilon )
\end{cases}
\end{eqnarray}$$
この誤差関数を\( \epsilon \)不感応誤差 1 と呼びます。2乗誤差よりペナルティが緩い誤差 2 になっています。この誤差関数の値は、 スラック変数\( \xi \) を使って以下の式で定義される領域の最小値として表すことが出来ます。
$$\begin{eqnarray}
A=\{ \xi \geq -z-\epsilon \}, \ \xi \geq 0 ,\ B=\{ \xi \geq z -\epsilon \}
\end{eqnarray}$$
誤差関数をグラフにすると、以下のようになります。A,Bが左右の傾きのある直線部分に対応します。
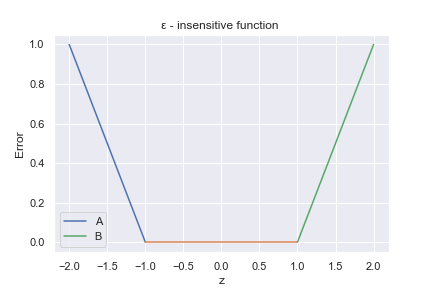
上の式を満たしながら、次の最小化問題を解くのがサポートベクトル回帰になります。
$$\begin{eqnarray}
\min \sum \xi + \lambda \sum \alpha ^{T} K \alpha
\end{eqnarray}$$
問題をラグランジュ未定乗数法の形にしましょう。
$$\begin{eqnarray}
L(\alpha , \beta , \gamma ^{+} , \gamma ^{-} ) &=& \sum \xi _i + \frac{\lambda}{2}\alpha ^{T}K \alpha \\
&-& \sum \beta _i \xi _i \\
&-& \gamma _i ^{+} (\xi _i + \epsilon -y_i + \sum K_{ij} \alpha _j ) \\
&-& \gamma _i ^{-} (\xi _i + \epsilon +y_i – \sum K_{ij} \alpha _j )
\end{eqnarray}$$
ただし、未定乗数( \( \beta _i \) とか)は0以上です。\( \alpha _i \) で微分して0 と置くことで、以下の関係を得ます。
$$\begin{eqnarray}
\alpha _i = \frac{1}{\lambda} ( \gamma _i ^{+} – \gamma _i ^{-} )
\end{eqnarray}$$
さらに、 \( \xi _i \) で微分して0と置くことで次の関係式が得られます。
$$\begin{eqnarray}
1 – \gamma _i ^{+} – \gamma _i ^{-} -\beta _i =0
\end{eqnarray}$$
得られた2つの関係式をLに代入することで、変数を消去することが出来ます。最終的に解くべき問題は以下の問題3です。
$$\begin{eqnarray}
L_{dual}(\gamma ^{+} , \gamma ^{-} ) &=& -\sum (\gamma _i ^{+} – \gamma _i ^{-})K_{ij} ( \gamma _j ^{+} – \gamma _j ^{-} ) \\
&-& \sum \gamma _i ^{-}(y_i + \epsilon ) – \gamma _i ^{+} (-y_i + \epsilon )
\end{eqnarray}$$
ただし、
$$\begin{eqnarray}
0 \leq \gamma _i ^{+} + \gamma _i ^{-} \leq 1
\end{eqnarray}$$
です。この制約下で\( \gamma _i ^{+} , \gamma _i ^{-} \)を求める事で、f(x) が決まります。
$$\begin{eqnarray}
f(x) =\frac{1}{\lambda} \sum_{x_i \in SV} ( \gamma _i ^{+} – \gamma _i ^{-} )k(x_i , x)
\end{eqnarray}$$
ただし、SVは、\( \gamma _i ^{+} , \gamma _i ^{-} \)どちらかが0とならない添え字全体です。
サポートベクトル回帰にもスパース性があります。以下で確かめましょう。
サポートベクトル回帰のスパース性
以下のラグランジュの未定乗数問題に対して、K.K.T条件を適用しましょう。4
$$\begin{eqnarray}
L_{dual}(\gamma ^{+} , \gamma ^{-} ) &=& -\sum (\gamma _i ^{+} – \gamma _i ^{-})K_{ij} ( \gamma _j ^{+} – \gamma _j ^{-} ) \\
&-& \sum \gamma _i ^{-}(y_i + \epsilon ) – \gamma _i ^{+} (-y_i + \epsilon )
\end{eqnarray}$$
K.K.T条件 から、\( ( \gamma _i ^{+} , -y_i + \epsilon ) \) のいずれかは0になり、\( (\gamma _i ^{-}, y _i + \epsilon )\)のいずれかも0になることが分かります。仮に、\( y_i +\epsilon = 0 \) が成り立てば、\( y_i – \epsilon \neq 0 \)なので、\( \gamma _i ^{+} =0 \)です。逆に、 \( y_i – \epsilon = 0 \)が成り立てば、 \( y_ i +\epsilon \neq 0 \) なので、 \( \gamma _i ^{-} =0 \) です。つまり、\( \gamma ^{+} , \gamma ^{-} \)のいずれかは必ず0になるのです。
各データ\(x_i \) が誤差関数のどこにいるのか考えてみましょう。
右側(下図B)に居るときは、\( z = y -f(x ) > \epsilon \)なので、\( y_i + \epsilon \neq 0 \)です。この時は、 \( \gamma _i ^{-} \neq 0 \)の可能性があります。
左側(下図A)に居る時は、 \( z = y -f(x ) < – \epsilon \)なので、\( – y_i + \epsilon \neq 0 \)です。 この時は、 \( \gamma _i ^{+} \neq 0 \) の可能性があります。
真ん中にいる時は、誤差関数が0になっているので、 \( \gamma _i ^{+} \) も \( \gamma _i ^{-} \) も0です。
つまり、サポートベクトルの集合は、誤差が\( \epsilon \)よりも大きいデータだけで構成されていることになります。下図のA,Bでは \( \gamma _i ^{-} , \gamma _i ^{+} \)が0でない可能性があります。
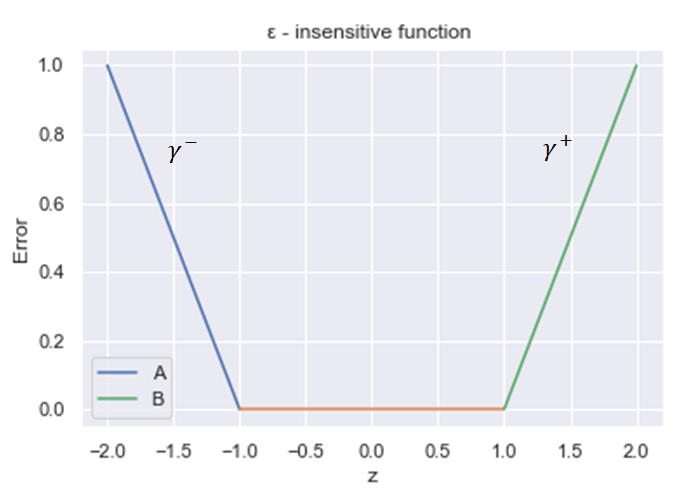
サポートベクトル回帰による予測
サポートベクトル回帰は、予測に使うデータが少なくなるので、過学習しにくいはずです。カーネル回帰と比べてみましょう。予測させるのはサインカーブに誤差を加えた関数です。カーネルリッジ回帰で使った関数と同じです。カーネル回帰やカーネルリッジ回帰については以下の記事をどうぞ。
早速実験してみましょう。
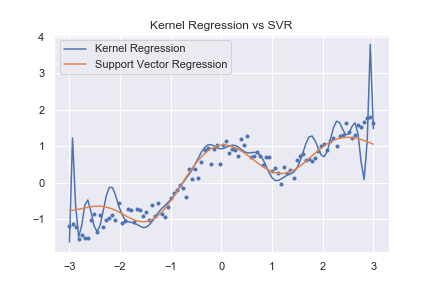
カーネル回帰は誤差を拾って過学習を起こしている事が分かります。一方で、SVRは殆ど過学習を起こしていません。汎化性能が高い事が分かります。人が見て、分布を大体とらえているのはどちらかと言われれば必ずSVRの方だと言うでしょう。
まとめ
- カーネル回帰モデル+ ε不感応誤差=SVR
- 双対問題を考える事で、SVRのスパース性、汎化性能の謎が解ける
- カーネル回帰と比べると、とても過学習しにくい
- SVCでは、ヒンジ関数を使いましたが。分類問題では、-1から1の間にしか予測値が無かったことを思い出しましょう。つまり、予測値は大きいか小さいかにしか意味がありません。そのことから、 \( \epsilon \)不感応誤差のように、両側にペナルティを持つ必要が無かった訳です。
- この段階で、カーネル回帰よりも、汎化性能が高いモデルであることが分かります。
- 元の問題に対する双対問題と言います。
- K.K.T条件に付いては以下の記事をご覧ください。
https://masamunetogetoge.com/svm-sparse
