
何かデータが与えられたら、グラフを描いたり基本的な統計量を出力してデータの素性を調べる、というのが第一ステップでは無いでしょうか。
時系列データの基本的な統計量に、自己相関係数があります。自己相関係数ををグラフにしたものは、コレログラムと呼ばれます。この記事では相関係数の簡単な性質をまとめ、pythonで実装します。また、コレログラムの描画をした後に、データのトレンド除去をします。
参考文献は一応3冊です。



記事で使っているソースコードはgithub に置いてあります。
https://github.com/msamunetogetoge
時系列データとは
データ全体の集合\( X \)が、時間と思われる添え字\( t = 0, \pm1 , \pm2 , \cdots \)で添え字づけられている時、時系列データと呼びます。tは有限個でも無限個でも構いません。
添え字が有限個でも時系列データと呼びます。例えば、GDPとか、株価とかです。毎日体重を計っていればそれも時系列データです。データは数字だけで、整数でも実数でも良いです。
そのようなデータが与えられたときに、未来の値を予測したり、データが右肩上がりかどうかを判断したりするのが時系列分析の一つの目的になります。
相関係数
時系列データに対して、相関係数が定義できます。\( \{ y_t \} _{t=0, 1 , , \cdots ,T } \)を時系列データとします。
$$\begin{eqnarray}
r(k) &=& \frac{ ( y_{+k} -\bar{y} ) \cdot (y_{-k} -\bar{y} )}{ \| y – \bar{y} \| ^2 }\\
\bar{y} &=& \frac{ \sum y_t}{T} \\
y &=& ( y_0, \cdots , y_{T} )\\
\bar{y} &=& (\bar{y} , \cdots , \bar{y} ) \\
y_{-k} &=& (\bar{y} , \cdots , \bar{y} , y_{0} , \cdots , y_{T} )\\
y_{+k} &=& ( y_0, \cdots , y_{T} , \bar{y} , \cdots , \bar{y} )
\end{eqnarray}$$
をk次の標本自己相関係数と呼びます。\(y_{\pm k} \)は、k個\(\bar{y} \)が前後に並ぶ事で、kだけ時間をずらして内積を取る役目を果たしています。 1
分子に出てくるのは\( T+k \)次元のベクトルで、分母は\(T \)次元のベクトルになっています。計算は、\( k+1 \)成分から\(T-k \)成分しか関係の無い事に注意してください。
自己相関係数の分子を
$$\begin{eqnarray}
\sigma (k ) = ( y_{+k} -\bar{y} ) \cdot (y_{-k} -\bar{y} )
\end{eqnarray}$$
と書き、 k 次の自己共分散と呼ぶこともあります。この記法を使えば、自己相関係数は以下のように書けます。
$$\begin{eqnarray}
r(k ) = \sigma (k) / \sigma (0)
\end{eqnarray}$$
自己相関係数や自己共分散には、以下の性質があります。
$$\begin{eqnarray}
(1&)& \sigma (0) \geq 0\\
(2&)& |\sigma (k) | \leq | \sigma (0) |\\
(3&)& \sigma (k) = \sigma (-k)\\
(4&)& | r(k) | \leq 1\\
(5&)& r(k) = r(-k)
\end{eqnarray}$$
一つずつ証明しましょう。
(1) は、ノルムなので良いでしょう。
また、(3)と(5) は、定義式で、 \(y_{+k} , y_{-k} \)の場所が入れ替わるだけなので、正しい事は明らかでしょう。
さらに、(2)が正しければ、(4)が相関係数の定義式から直ちに従います。
という訳で、真面目に考える必要があるのは(2)だけです。
$$\begin{eqnarray}
\sigma (k) ^2 &=& \| ( y_{+k} -\bar{y} ) \cdot (y_{-k} -\bar{y} ) \| ^2 \\
&\geq & \| y_{+k} -\bar{y} \| ^2 \cdot \| y_{-k} -\bar{y} \| ^2 \\
&=& \sigma (0) ^2
\end{eqnarray}$$
ただし、不等式はコーシーシュワルツの不等式です。最後の等号は定義に戻ると分かります。2
という訳で、時系列データにおいては、\(t=0 \)の分散や相関係数が最大であることが分かります。このことは、より過去や未来に行けば行くほど相関が小さいとか、分散が小さいとかを示しているわけでは無い事に注意しましょう。
pythonによる実装
国のページにあるGDPのグラフを描いて、自己相関係数を計算してみます。また、 \( r(0) , r(1) , \cdots \)をグラフに描いたものを コレログラムと呼びますが、これを描いてみましょう。
まずは自己相関係数を計算する関数を作っておきます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
def autcor(X, k):
X_bar = np.mean(X)
X_bar_k = X_bar * np.ones(k)
X_k = np.append(X_bar_k ,X)
k_X = np.append(X, X_bar_k )
r= np.dot(X_k -X_bar , k_X - X_bar )
r/= np.linalg.norm(X-X_bar)**2
return r定義式をそのまま書いただけです。GDPのデータは、以下のグラフのようになっています。
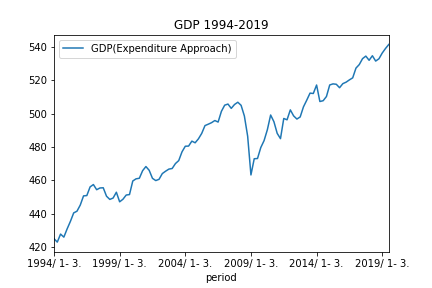
基本的に右肩上がりで、周期的に下がっているかな?という感じのグラフです。どのくらいの周期でGDPが下がっているのか気になる所です。
コレログラムを描いてみましょう。
Aut_r =[]
for i in range(10):
r = autcor(X["GDP(Expenditure Approach)"],i)
Aut_r =np.append(Aut_r, r)
plt.stem( Aut_r, use_line_collection=False)
plt.title("Aut Correlation Coeficiebt")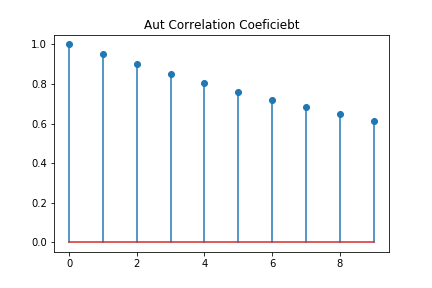
元のグラフが右肩上がりのグラフなので、10次まで非常に大きな相関を持っています。これではデータの細かい情報を拾うのは無理そうです。
さらに高次の相関係数はどうでしょうか。pandas には、相関係数を計算できるだけ計算して、グラフを描いてくれる関数があります。
pd.plotting.autocorrelation_plot(X["GDP(Expenditure Approach)"], )
plt.title("pandas Autcorrelatiob function")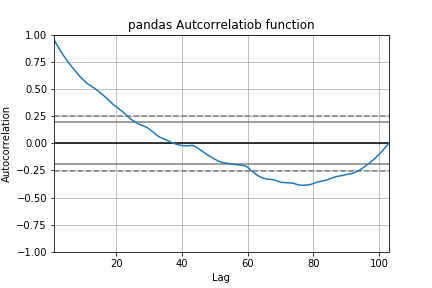
40次くらいまで計算してようやく負の相関が見え始めました。元のデータを加工しないと、意味のある情報は得られないようです。3右肩上がりのような、直線的な傾向の事をトレンドと呼びます。時系列データは、トレンドを除去してから解析するのが普通です。(多分)
という訳で、トレンドを消去してコレログラムを描いてみましょう。
トレンド除去
トレンド除去の主な方法には、以下の2つがあります。
- 対数や平方根を取る。
- 階差を取る。
対数や平方根を取ると、データ全体のバラツキを慣らす事が出来ます。階差を取ると、 右肩上がりなどの傾向を軽減することが出来ます。
\( \{ y_t \}_{t=0, 1,\cdots , T } \) のk階の階差を取るとは、以下の操作を言います。
$$\begin{eqnarray}
\{ y_t \} \rightarrow \{ y_{k+1} – y_{1} , \cdots , y_{T}- y_{T-k} \}
\end{eqnarray}$$
階差を取る事によるトレンド除去については、以下のように考える事が出来ます。
\( \{y_t \} \)が
$$\begin{eqnarray}
y_t = at +b
\end{eqnarray}$$
と表されるとしましょう。1階の階差を取ると、
$$\begin{eqnarray}
y_t – y_{t-1} = a
\end{eqnarray}$$
隣り合ったデータの間1次関数のトレンドが除去できる事が分かります。4
今回のデータは、4半期毎に明らかな平均値の変動5があるので、4階の階差を取るのが大事です。
今回は、平方根を取って、1階の階差を取り、4階の階差を取ります。階差は、pandas の.shift()を使うと楽に取れます。
X["sqrtGDP"]=np.sqrt(X["GDP(Expenditure Approach)"])
plt.plot(X["sqrtGDP"])
plt.title("sqrt GDP")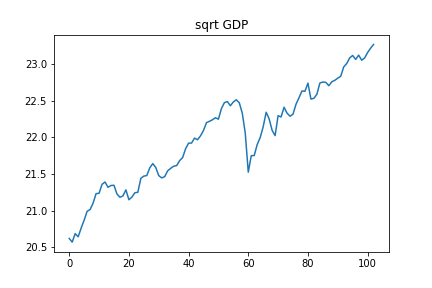
平方根を取ることで、全体的にデータのギザギザ感が減りました。次に、1階の階差を取ります。
X["shiftGDP"] = X["sqrtGDP"]-X["sqrtGDP"].shift(1)
plt.plot(X["shiftGDP"])
plt.title("shift GDP")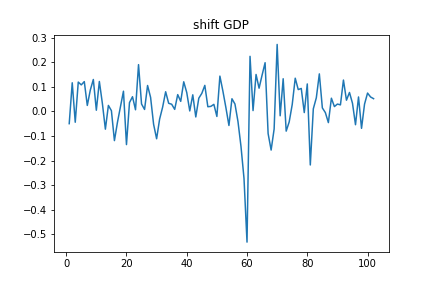
右肩上がりのトレンドは完全になくなりましたが、1年(=データ4個) 毎に平均値が上がったり下がったりしています。この傾向をなくすために、4階の階差を取って、コレログラムを描いてみます。
X["seasonGDP"] = X["shiftGDP"] - X["shiftGDP"].shift(4)
plt.plot(X["seasonGDP"])
plt.title("season GDP")
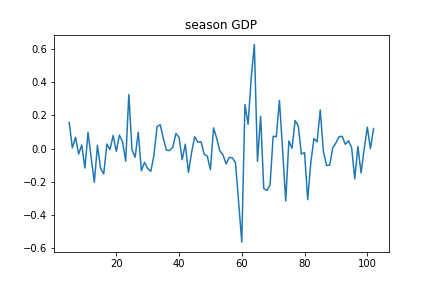
1階の階差を取ったデータより、さらにトレンドが除去されました。最後にコレログラムを描いてみます。
Aut_r =[]
for i in range(10):
r = autcor(X["seasonGDP"].dropna(),i)
Aut_r =np.append(Aut_r, r)
plt.stem( Aut_r, use_line_collection=False)
plt.title("Aut Correlation Coeficiebt")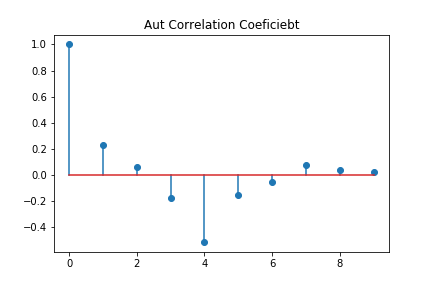
データを加工する前と比べて、それっぽい図になりました。\( r(4) \)が最も大きな値です。これは、1年前のGDPと現在のGDPに大きな相関があることを示しています。
まとめ
- 時系列データについて説明した
- 時系列データの相関係数について説明した
- 適当なデータのコレログラムを描いた
- トレンド除去してコレログラムを描いた

