
時系列データを予測するために、簡単な確率モデルを考えます。モデルを考える上では、確率過程を使います。その中で、定常確率過程が大事です。今回の記事では、定常な時系列モデルであるMAモデルを解説します。
参考文献は一応3冊あります。



記事で使っているソースコードはgithub に置いてあります。
https://github.com/msamunetogetoge
確率過程と定常性
初めに、確率過程と、定常性について説明します。確率過程の具体例としては、ガウス過程が挙げられます。ガウス過程の基本的な性質や、ガウス過程回帰などの説明記事があるので読んでみてください。

確率過程とは、確率分布の列\( \{ p_t \}_{t \in I } \)の事です。ただし、\(I \)は添え字集合で、整数全体だったり、自然数全体だったり、実数全体だったりと、好きなモノを使います。時系列データでは、整数全体と思う事が多いかもしれません。
次に、定常性について説明します。
確率分布と確率変数があると、期待値が取れますが、時系列データを念頭に置いた確率過程で大事なのは(共)分散と平均です。
各 \( t\)に対して、\(x_t \sim p_t \) とするとき、平均や分散は以下の式で定義されます。
$$\begin{eqnarray}
\mu _t &=& E[x_t ]\\
\sigma _t &=& E[ (x_t – \mu _t )^2 ]\\
\sigma (t, s ) &=& E[ (x_t – \mu _t ) (x_s – \mu _s ) ]
\end{eqnarray}$$
定常な確率過程とは、以下の性質を満たすものをいいます。
[定常確率過程]
- 任意の \(t , s \)に対して、 \( \mu _t = \mu _s \)
- 任意の \(t , s \)に対して、 \( \sigma (t, s ) \) は、\(t-s \)にのみよる。つまり、共分散が、 \( \sigma (t, s ) = \sigma _{t-s} \)とかける。
定常でない確率過程は、非定常な確率過程と呼びます。
定常な確率過程においては、
$$\begin{eqnarray}
\sigma _t &=& \sigma (s,s-t ) \\
\sigma _0 &= & \sigma (1,1) = \cdots =\sigma (t,t ) \cdots
\end{eqnarray}$$
が成り立つ事に注意しましょう。2つ目は、分散がどの時点でも等しいという事で、結構大きな制約になっています。簡単には、定常な確率過程とは、分散と平均値が時間に依存しない確率過程という事になります。
定常な確率過程\( p_t \)に対して、自己相関係数\(\rho _t \)を以下で定義します。
$$\begin{eqnarray}
\rho _t = \sigma _{t} /\sigma _0
\end{eqnarray}$$
\( x_t \)たちが、確率分布からサンプリングして得られた標本だとすると、標本に対する平均値や(共)分散を考える事で、相関係数の記事に出てきている式が再現される事に注意してください。
https://masamunetogetoge.com/timeseries-rolling-cor
重要な定常確率過程の一つに、ホワイトノイズがあります。
[ホワイトノイズ]
確率過程 \( \{ \epsilon _t \} \)が以下を満たすとき、ホワイトノイズと呼ぶ。
- 全てのtに対して \( E[ \epsilon _t ] =0 \)
- \( E[\epsilon _t \epsilon _{t-k}] = \left\{ \begin{array}{ll} \sigma ^2 & (k=0) \\ 0 & ( k \neq 0 ) \end{array} \right. \)
\( \{ \epsilon _t \} \)が分散\( \sigma ^2 \)のホワイトノイズに従う事を、
$$\begin{eqnarray}
\epsilon _t \sim {\rm W.H. }(\sigma ^2 )
\end{eqnarray}$$
で表します。
ホワイトノイズは、時系列モデルを作成する際に、確率過程を生成する役割を果たします。線形回帰の、正規分布に従う誤差項みたいな使い方です。

定常な確率過程からサンプルすると、平均値が一定なので、サインカーブみたいなグラフが描かれます。非定常だと、サイン+直線、のようなグラフになります。相関係数の記事でトレンドという言葉が出ましたが、トレンドあるなし、というのは定常or非定常という事です。定常な確率過程と、非定常な確率過程のグラフを載せておきます。

MAモデル
MAモデルについて説明します。
MAは、Moving Average process の略で、日本語では移動平均モデルとか呼ばれます。\( \{\epsilon _t \} \)をホワイトノイズとします。
$$\begin{eqnarray}
y_t = \mu +\epsilon _t + \theta _1 \epsilon _{t-1} + \cdots + \theta _q \epsilon _{t-q}
\end{eqnarray}$$
をMA(q) モデルと呼びます。ただし、\(\mu, \theta _1 , \cdots , \theta _q \) は定数 です。MA(q) モデルの\( \{y_t \} \)は、\( \epsilon _t \)により確率過程になっています。また、\(y_t \)たちは、 \(\epsilon _t \)によって相関を持っています。
MA(1)モデルで少し遊んでみましょう。
\( y_t = \mu +\epsilon _t + \theta _1 \epsilon _{t-1}\)で 期待値や分散を考えます。
$$\begin{eqnarray}
E[y_t] &=& \mu \\
V[y_t ] &=&V[ \mu +\epsilon _t + \theta _1 \epsilon _{t-1} ]= V[\epsilon _t ] + \theta _1 ^2 V[\epsilon _{t-1}]\\
&=& (1+ \theta _1 ^2 )\sigma ^2 \\
\sigma _1 &=& Cov(y_t , y_{t-1} ) =Cov(\theta _1 \epsilon_{t-1}, \epsilon_{t-1} )\\
&=& \theta _1 \sigma ^2 \\
\sigma _k &=& Cov(y_t , y_{t-k} ) =0 (k\geq 2)
\end{eqnarray}$$
\(\sigma _2 \)以降は、ホワイトノイズがお互いに無相関であることから出ます。上の計算から、MA(1)モデルの自己相関係数が計算出来ます。
$$\begin{eqnarray}
\rho _k = \left\{ \begin{array}{ll} \theta _1/(1+\theta _1 ^2 ) & (k=1) \\ 0 & ( k \geq 1 ) \end{array} \right.
\end{eqnarray}$$
MA(1)モデルは、1次の自己相関のみがある確率過程になっています。また、定常確率過程でもあります。1
:計算で使ったのは分散の線形性だけなので、MA(q) モデルの平均値や分散も計算出来ます。2
[MA(q)モデルの平均値、分散]
$$\begin{eqnarray}
E[y_t] &=& \mu \\
V[y_t ] &=& (1+ \theta _1 ^2 + \cdots + \theta _q ^2 )\sigma ^2 \\
\sigma _k &=& \left\{ \begin{array}{ll} (\theta _k +\theta _{1} \theta _{k+1}+ \cdots \theta _{q-k} \theta _{q} )\sigma ^2 & (1\leq k\leq q) \\ 0 & ( k \geq q+1 ) \end{array} \right. \\
\rho _k &=& \left\{ \begin{array}{ll} \frac{\theta _k +\theta _{1} \theta _{k+1}+ \cdots \theta _{q-k} \theta _{q} }{ 1+ \theta _1 ^2 + \cdots + \theta _q ^2 } & (1\leq k\leq q) \\ 0 & ( k \geq q+1 ) \end{array} \right.
\end{eqnarray}$$
\(\sigma _k \)は、kが大きくなるほど、足されるパラメーターの数が減っていく事に注意しましょう。
MA(q)モデルは、どんなqでも、どんなパラメーターを取っても、定常確率過程であることが分かります。また、MA(q)モデルは、q次以降の自己相関係数が0になる”人工的”なモデルである事に注意しましょう。決めるべきパラメーターが\( \mu, \theta _1 , \cdots , \theta _q \)と\(q+1 \)個あることにも注意です。
Python による実装
python でMA過程がどんな感じか描いてみます。
初めに、適当にパラメーターを決めてMA(1)モデルで時系列データを生成し、自己相関係数が1次以降0になることを確認します。
def autcor(X, k):
X_bar = np.mean(X)
X_bar_k = X_bar * np.ones(k)
X_k = np.append(X_bar_k ,X)
k_X = np.append(X, X_bar_k )
r= np.dot(X_k -X_bar , k_X - X_bar )
r/= np.linalg.norm(X-X_bar)**2
return r
#MA(1)モデルで時系列データを生成
theta =0.8
sig =1
mu=0
T=10000
epsilon = np.random.normal(loc=0, scale=sig, size=T+1)
y0=0
Y=np.zeros(T+1)
Y[0]=y0
for i in range(T):
Y[i+1] = mu+epsilon[i+1]+theta * epsilon[i]
Y= Y[1:]
#自己相関係数を計算
Aut_r =[]
for i in range(20):
r = autcor(Y,i)
Aut_r =np.append(Aut_r, r)
plt.stem(Aut_r[1:], use_line_collection=False)
plt.title("Aut Correlation Coeficient MA(1)")
plt.savefig("MA1_10000.png")
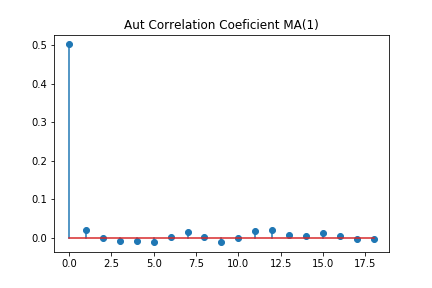
データを10000個作っているので、何がなんだか分かりませんが、1次以外はほぼ0という結果になっています。次に、MA(5)モデルでも同じことをしてみましょう。データを100個使った場合と、データを10000個使った場合でやってみます。
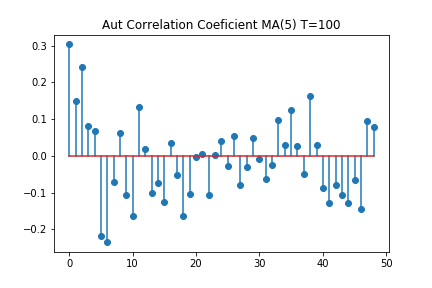
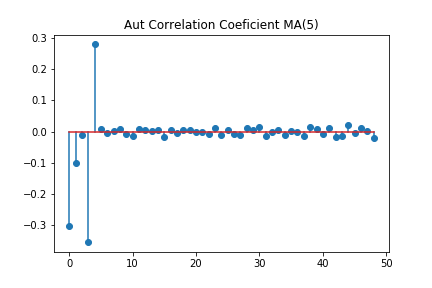
データ数100個のグラフを見ると、何かパターンがあるような気もします。しかし、自己相関係数を見ると、5次以降も、大きな相関がある結果になっています。一方で、データ数10000では、グラフ上は良く分かりませんが、相関係数は5時以降はほぼ0ということになっています。
時系列データは、統計的有意性を出すのに大量のデータが必要なようです。3
まとめ
- 定常確率過程について説明した
- MAモデルについて説明した
- MAモデルは常に定常な確率過程を生成する
- MAモデルから時系列データを生成し、自己相関係数の次数をコントロール出来るか確かめた
