
機械学習やデータ分析をする上で避けて通れないのがデータの前処理です。アプリを作るシリーズで扱った前処理をまとめています。アプリを作るシリーズは以下から読めます。

欠損値の扱い
人が取ったデータにはほぼ確実に欠損値やタイプミスが含まれます。これをどう処理するか定番の方法があります。
欠損値の割合が少ない場合
全体のデータの中で、欠損値を含むデータが殆どない場合は、単純に欠損値を省く事が多いです。pythonでは、pandas のdropnaで実行できます。
ラベルの扱い
文字データのラベル化
生データでは、英数字の羅列で商品などが管理されている事が多いです。例えばティファールの電気ケトルについている BF805170 などです。
この時、文字のままだと機械学習で処理できないので、必要に応じて文字の一部分を切り取ってラベルにします。 BF805170 だったら、最初の文字のBFを抜き取っておきます。
タイタニック号の生存者に関するデータで例を見てみます。

タイタニック号事故の生存率には、年齢と性別が大きく関わっています。名前に大体Mr. とMs. とかが付いていて、その部分が有効な特徴量になります。
名前のデータから、その部分をラベルとして取り出します。以下のように書けます。
import pandas as pd
df = pd.read_csv('train.csv')
df['Title'] = df.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
Title という列を新たに生成して、そこにMr.とかを入れてます。 1 extract はpandas で正規表現を使う時の関数です。正規表現については以下のサイトを見てください。文字の塊+ .(ドット)の形の文字の集合を検索してます。

ラベルの数値化
ラベルにしても、ラベルのままでは機械学習のモデルに与える事は出来ません。という訳で、ラベルを数字にしなくてはいけません。そのような処理をone hot encoding と言います。titanic のデータでは、Embarked のデータがその対象になります。
やり方としては、pandasのget_dummies があります。
Emb = pd.get_dummies(df.Embarked)
df=pd.concat(df, Emb], axis=1)
数値の正規化
機械学習の理論には、データが正規化された前提の物があります。そのような手法を用いない場合でも、特徴量の分布に大きな偏りがあると解析が上手くいかない場合が多数です。
ポピュラーなやり方としては、特徴量の平均を引いて、分散で割ります。
titanic データの Fareを正規化してみます。2
fare = df.Fare
norm_fare = (fare - fare.mean() )/ fare.std()
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
sns.distplot(fare)
plt.subplot(1,2,2)
sns.distplot(norm_fare)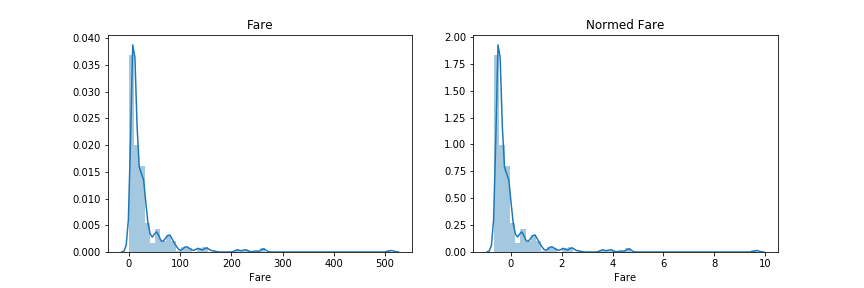
殆どが0~100に固まっていた分布が0~2に縮まりました。分布の形自体は変わっていないことに注意が必要です。
今回のアプリ作成で行った前処理は以上です。定番の物はもう少しあるので、機会があれば記事にしたいと思います。
まとめ
- 欠損値を処理した
- 文字列から必要なラベルを抜き出した
- ラベルをベクトルに変換した
- 正規化した

