
機械学習の困りごとの一つとして、結果の解釈が難しい、という事があります。
特徴量が結果に与える効果を評価する術が存在するので、結果の解釈が出来たりすることが多いです。
記事では、以下の方法を紹介します。モデル毎に使える時と使えない時があるので注意1しましょう。
- t値
- ジニ係数
- permutation importance
- heat map
記事で使っているソースコードはgithub に置いてあります。
https://github.com/msamunetogetoge
t値
始めはt値を解説します。実務では回帰だけで事足りることが多いと思いますが、特徴量の効果を測る方法の一つに、t値があります。2
t値は、大きければ大きい程回帰係数に意味がある と思うと良いです。
定義を確認し、python 上で表示してみましょう。
t値の定義
簡単の為に、単回帰分析の場合で考えましょう。
$$\begin{eqnarray}
y &\sim & \hat{\beta _0 }+ \hat{\beta _1 } x +\epsilon \\
\epsilon &\sim & \mathcal{N}(0, \sigma ^2)
\end{eqnarray}$$
を仮定します。\( \epsilon \)に関する最小2乗法によって、回帰係数が\( \beta _0 , \beta _1 \)と予測された3 としましょう。回帰係数の予測式の形から、回帰係数の従う確率分布は以下のようになります。
$$\begin{eqnarray}
\hat{\beta _0} \sim \mathcal{N}\left( \beta _0 , \frac{ \sum x_i ^2}{n\sum( \bar{x} -x_i)^2} \right) \\
\hat{\beta _1} \sim \mathcal{N} \left( \beta _1 , \frac{ \sigma ^2}{\sum( \bar{x} -x_i)^2} \right)
\end{eqnarray}$$
正規分布\( \mathcal{N}(\mu ,\sigma^2 ) \)から抽出したN個のサンプル\( \{ X_i \} \) があった時、不偏分散を\(s^2 = \frac{1}{N-1} \sum (X_i – \bar{X} )^2 \)として、以下の量をt値4呼びます。
$$\begin{eqnarray}
t(N-1) =\frac{\bar{X} -\mu }{\frac{s}{\sqrt{N}}}
\end{eqnarray}$$
サンプル数Nが決まる事で、 このt値は自由度N-1 のt-分布に従います。t値までの積分値によって、p値が決まり、統計的に有意な結果かどうかを判断できます。
回帰分析の場合に戻りましょう。\( \hat{\beta _1} \)について考えましょう。分布は既に推定できている感じがしますが、残差の分散\(\sigma ^2 \)は分かりません。そこで、残差について不偏分散を計算しましょう。残差は期待値が0だったり、特徴量たちと直交していたりするので、データ数Nに対して自由度はN-2 5です。よって、残差は以下のようになります。
$$\begin{eqnarray}
s^2 = \sum e_i ^2 /N-2
\end{eqnarray}$$
従って、\( \hat{\beta _1 } \)の不偏分散は以下のように推定できます。
$$\begin{eqnarray}
s_{\beta} ^2 = \frac{s^2}{\sum (X_i -\bar{X} )^2}
\end{eqnarray}$$
これから、計算するべきt 値は、
$$\begin{eqnarray}
t(N-2) = \frac{ \hat{\beta _1 } -\beta _1 }{ s_{\beta} }
\end{eqnarray}$$
となります。不偏分散は残差由来なので、自由度は N-2 です。大体の場合は、\( \beta _1 =0 \)としうて、回帰係数に意味があるかどうかで検定をします。
python で適当なデータを使ってt値を表示させましょう。
python による計算
Rに標準で入っているDavis データを使います。性別と体重から身長を予測します。身長を予測するなら、性別より体重を見た方が良い気がしますが、t値に反映されているか見ましょう。データは加工済みとして、sklearn にt値とp値を計算する関数を書き足して計算してもらいましょう。
from sklearn import linear_model
from scipy import stats
import numpy as np
import pandas as pd
#Davisデータの読み込み
#sheet1が全Davis データ
sex = pd.get_dummies(sheet1.sex)
x=pd.concat([sheet1.repwt, sex], axis=1)
y= np.array(sheet1.repht).reshape(-1,1)
class LinearRegression(linear_model.LinearRegression):
"""
LinearRegression class after sklearn's, but calculate t-statistics
and p-values for model coefficients (betas).
Additional attributes available after .fit()
are `t` and `p` which are of the shape (y.shape[1], X.shape[1])
which is (n_features, n_coefs)
This class sets the intercept to 0 by default, since usually we include it
in X.
"""
def __init__(self, fit_intercept=True, normalize=False, copy_X=True,
n_jobs=1):
self.fit_intercept = fit_intercept
self.normalize = normalize
self.copy_X = copy_X
self.n_jobs = n_jobs
def fit(self, X, y, n_jobs=1):
self = super(LinearRegression, self).fit(X, y, n_jobs)
sse = np.sum((self.predict(X) - y) ** 2, axis=0) / float(X.shape[0] - X.shape[1])
se = np.array([
np.sqrt(np.diagonal(sse[i] * np.linalg.inv(np.dot(X.T, X))))
for i in range(sse.shape[0])
])
self.t = self.coef_ / se
self.p = 2 * (1 - stats.t.cdf(np.abs(self.t), y.shape[0] - X.shape[1]))
return self
lm = LinearRegression()
lm.fit(x,y)
v = np.array([lm.t, lm.p]).reshape(2,3)
V=pd.DataFrame(v, index=["t-value", "p-value"], columns=["weight","F", "M"])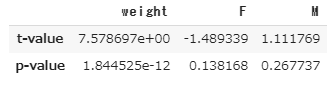
t値を見てもp値を見ても体重が大きく効いていることが分かります。t値はこんな感じに使います。
ジニ係数(Gini Index)
ジニ係数とは、tree 系の機械学習手法で使われる指標です。tree diagram(正式な呼び方は分かりませんが)のノード毎に、ジニ係数が計算出来ます。ジニ係数それ自体でなく、減少量を見る事で、どの特徴量が重要か判定できます。初めに、ツリー系のモデルの作り方について簡単に解説しておきます。相手の持っている知識を確認して、友達になるか決めるモデルを考えましょう。6
ツリー系には、木を成長させたり伐採するアルゴリズムが色々ありますが、大体は下の写真のような木が出来ます。
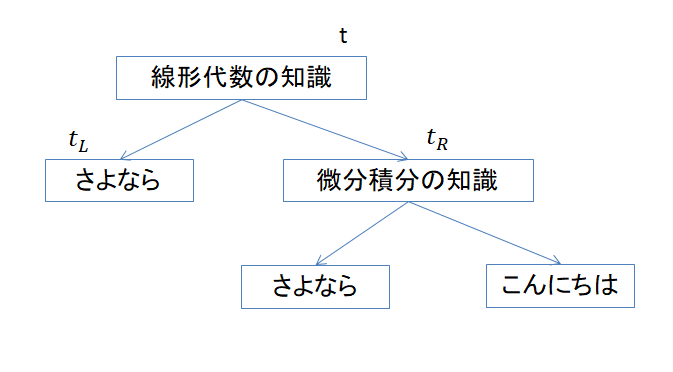
t と書いてあるのが、今注目している部分です。木の特徴として、左右に枝を伸ばす事があります。それを\( t_L , t_R\)と書いています。ツリーでは、不純度と呼ばれる量で、木の成長や伐採を行います。7t での不純度を\( \mathcal{I}(t) \) と表すと、その部分でのゲイン(勾配みたいなもの)が以下の式で計算出来ます。
$$\begin{eqnarray}
\Delta = \mathcal{I}(t) – (p_L \mathcal{I}(t_L) + p_R \mathcal{I}(t_R) )
\end{eqnarray}$$
ただし、\( p_L , p_R \)は \(t_L , t_R\) に含まれるデータの割合を表しています。
ゲインを最大にするような分割の仕方を全てのt について見つける事で、モデルが完成します。
ジニ係数の計算
tでのジニ係数は以下のように定義されます。
$$\begin{eqnarray}
\mathcal{I}(t) = 1- \sum_{i=1} ^{c} (\frac{n_i}{N} )^2
\end{eqnarray}$$
\( N \)はデータの総数, \( c \)はクラスの数8, \(n_i \)は 各クラスに含まれるデータの数です。
各tで、持っている特徴量毎に計算をして、ゲインが最大となるように木を作っていきます。モデルが出来た後に、各tでのジニ係数を平均することで、モデル全体としての特徴量毎のジニ係数が算出できます。
python での計算
アヤメの分類のデータ(iris data )をランダムフォレストで分類し、特徴量の重要度を測ってみます。
#大事な部分だけ載せておきます
#tree 系のモデルでは、大体.feature_importances_ で特徴量の重要度を算出できます。
from sklearn.ensemble import RandomForestClassifier
rf= RandomForestClassifier()
rf.fit(x_train, y_train)
fi = rf.feature_importances_
for i, feature in enumerate(iris.feature_names):
print("{}: {}".format(iris.feature_names[i], fi[i]))
"""
sepal length (cm): 0.016242694506877653
sepal width (cm): 0.005806186912088151
petal length (cm): 0.3748501903046553
petal width (cm): 0.603100928276379
"""
どうやら花弁の幅が大事みたいです。 こんな感じに重要度を測る事が出来ます。tree 系では、重要という事は分かりますが、その特徴量が大きくなった時にラベルがどう動くかは分かりません。データを眺めれば分かるわけですが、偉い人たちは大体分からんとか言う訳です。
そんな時に、eli5 です。9
Permutation Importance(eli5)
英語の略語でeli5 というものがあります。”Explain Like I’m 5″ の略語ですが、誰にでも分かるように説明してくれという感じの意味10ですね。
permutation importance は以下のように計算されるようです。
- 現在の特徴量とラベルを記憶しておく
- 評価する特徴量を一つ選ぶ
- その特徴量を行方向にシャッフルする。
- ラベルがどれだけ変わったか記録する
- 全ての特徴量について3,4を行う
ある特徴量を動かしたときに、ラベルの値が大きく変われば、その特徴量が大きな効果を持っているという訳11です。
実際にpythonでやってみましょう。ジニ係数と同じ感じになるかも調べてみます。
import eli5
from eli5.sklearn import PermutationImportance
rf = RandomForestClassifier().fit(x_train, y_train)
perm = PermutationImportance(rf, random_state=1).fit(x_test, y_test)
eli5.show_weights(perm, feature_names = iris.feature_names)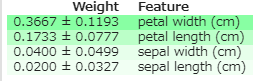
ジニ係数では、petal width > petal length>他 という順に重要と言うことになっていましたが、同じような結果が出ています。eli5 の良い所は、その特徴量が+ の影響を与えるのか-の影響を与えるのかまで表示してくれるところです。
kaggle の記事では他にも特徴量の評価方法を紹介しています。SHAP value も見やすくて便利です。
使うモデル毎に、関数が違うので注意が必要です。
import shap
explainer = shap.TreeExplainer(rf) #ツリー系、ニューラルネット系、カーネル系で違う関数を使います。
data_for_prediction =df.iloc[3]
shap_values = explainer.shap_values(data_for_prediction)
print(y_train[3])
#0
shap.initjs()
shap.force_plot(explainer.expected_value[1], shap_values[1], data_for_prediction)
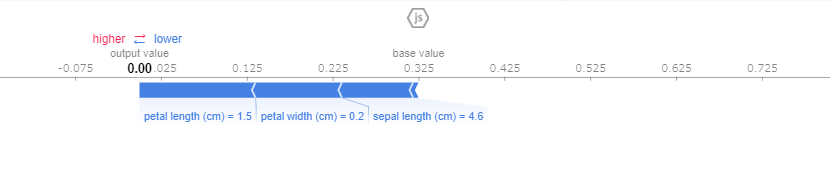
予測値が0である理由がグラフで示されています。 今回はラベル量ですが、連続量で使うと直感的に見やすく、便利です。
Heat Map
今までは主に、1次元の特徴量の話でしたが、heat map は画像認識の分野の話12です。やることは単純で、特徴量の勾配を計算して、元の画像と一緒に表示するだけです。そうすることで、モデルが元画像のどこに注目しているのかが分かります。
python でやってみましょう。13cnn モデルでkeras のbackend関数で勾配を取得してヒートマップを取得し、元の画像に貼り付けます。
書跡のgithubのコードを移しただけなので、私のgithubか本家 を見てください。14とりあえず 結果だけ貼ります。


モデルは画像をアフリカ象と判断しました。勾配の大きい部分を塗りつぶすと、小象の鼻と耳の間が赤くなっています。どうやらその辺りでアフリカ象と認識したようです。
この手法は結構使い勝手が良くて、工場とかで画像検査を導入するときに、ヒートマップの機能があるだけでとても喜ばれます。
まとめ
- 回帰係数の評価のため、t値の計算方法と意味を解説した
- ツリー系のモデルで特徴量を評価するジニ係数を解説した
- permutation importance のpython での計算方法を解説した
- heat mapを表示した
- 大体はライブラリに付随しているので、自分で何か考える必要は殆どありません。
- 分散分析をしてF値を見るのも同じ意味です。\( F= t^2 \) の関係があります。
- 具体的な式は単回帰分析の記事に書いてます。
- 分散が未知の正規分布がある時に、平均が従う分布を推定したくて、不偏推定量で分散を推定しておいて標準正規分布を作る感じですね。平均を取っているので、\( \sqrt{N} \)で割る必要があります。
- 単回帰分析の記事で解説してます。
- 現実に居たらやばいやつですね。
- 他の機械学習でいう損失関数です。
- 上の例では2
- 必ずしもtree 系の結果とは一致しませんが、大きくはずれたのを見たことがありません。
- 社会でめちゃくちゃ要求される能力だったりしますね。
- この評価方法は、kaggle のデータセットやカーネルで遊んでいる時に目にしたもので、理論的な詳細は知りません。 理論的な背景を知らずに紹介するのは心苦しいのですが、めっちゃ便利なので紹介します。詳細が書いている文献があれば教えてください。元ネタのリンクを貼っておきます。https://www.kaggle.com/learn/machine-learning-explainability
- 画像の1個1個の数字を特徴量だと思います。
- ネット上に同じような記事が乱立しているので、書く必要が無いかもしれませんが。
- 本家のリンクを貼っておきます。

