
エクセルにまとめられているような、横長のデータを縦長に変換する関数がpandasにあります。それがmeltです。meltの使い方について解説します。
melt関数を使う
初めにpandas.melt のドキュメントのリンクを貼っておきます。

使うデータは下の画像のようなデータです。1
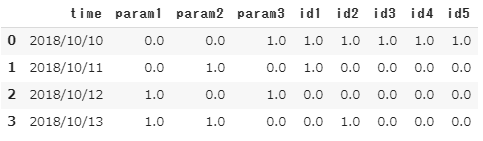
データは適当に作ったものです。
想定としては、実験データをexcelにまとめていて、timeからparam3 が実験の条件で、id1からid5が測定結果と、測定ヶ所を表しています。
このデータで、id1からid5という条件にも意味があり、さらに特徴量として扱いたい時にmelt関数が使えます。
例えば以下のように書くと所望の結果が出ます。
pd.melt(df,id_vars=df.columns.values[:4],var_name="id",value_name="massure" )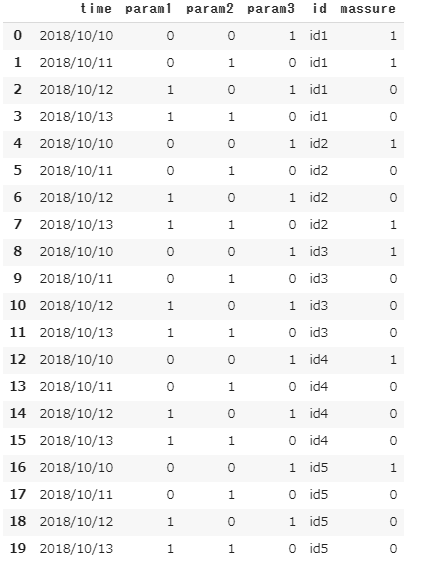
下記でmelt関数の引数の意味や性質について少し説明します。
melt関数の説明
公式ドキュメントでは以下のように説明されています。
pandas.melt(frame: pandas.core.frame.DataFrame, id_vars=None, value_vars=None, var_name=None, value_name=’value’, col_level=None) → pandas.core.frame.DataFram
Unpivot a DataFrame from wide to long format, optionally leaving identifiers set.
This function is useful to massage a DataFrame into a format where one or more columns are identifier variables (id_vars), while all other columns, considered measured variables (value_vars), are “unpivoted” to the row axis, leaving just two non-identifier columns, ‘variable’ and ‘value’.
分かるような分からないような書き方ですが、以下のようなことが出来ます。2
- データの列をid_vars, variable, value の3つの集合に分ける。
- id_vars に指定した列はそのまま
- values_vars に指定した列名はデータとして扱われ、variable列に格納される
- variable列の名前はvar_nameで変更する
- value_vars に入っていたデータが、value列に格納され、アンピボットされる
- value列の名前はvalue_nameで変更する
コード再読
この説明を元に、もう一度最初に挙げたコードを見ましょう。
pd.melt(df,id_vars=df.columns.values[:4],var_name=”id”,value_name=”massure” )
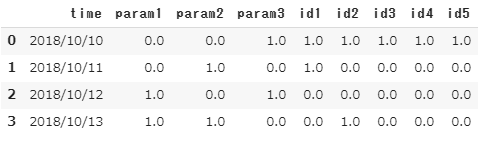
左から順に意味を解読すると、
- dfを呼び出してアンピボットしています。
- id_vars をtimeからparam3までで、設定しています。
- variable_vars は指定していないので、valiable列にid1からid5がデータとして格納されます。
- var_name=”id”としているので、variable 列の名前は”id”になります。
- id1からid5に入っていたデータはvalue列に格納されます。
- value列の名前はvalue_name=”massure” で、”massure”になります。
思ったこと
エクセルにまとめたデータを機械学習や統計処理に突っ込むときに便利そうな関数です。
- githubに置いておきます。
- マルチインデックスにも対応しているみたいですが、マルチインデックスはほとんど使わないので解説しません。
