
安定してデータを取れているような状況での異常検知の手法として、マハラノビス距離があります。データの次元が大きくなるほど感度が小さくなっていくという特徴があるので、微妙な値の変化を捉えるのは向いていないかもしれませんが、安定したデータにめちゃくちゃな値が入ってくるような状況では力を発揮します。
マハラノビス距離とは
マハラノビス距離の定義をします。
一般に、\( m\)次元のベクトル\(x,y \)と正則行列\( \Sigma \)があるとき、
$$\begin{eqnarray}
d_{\Sigma } (x,y ) &=& \sqrt{(x-y)^T \Sigma ^{-1}(x-y) }
\end{eqnarray}$$
をマハラノビス距離と呼びます。これは、数学的な意味で距離になります。つまり、以下の性質を満たします。
$$\begin{eqnarray}
d_{\Sigma } (x,y ) &\geq & 0 \\
d_{\Sigma } (x,y ) &=& 0 \Leftrightarrow x=y \\
d_{\Sigma } (x,y _1 + y_2 ) &\leq & d_{\Sigma } (x,y _1 ) + d_{\Sigma} (x, y_2 )
\end{eqnarray}$$
最後の不等式は、\((x,y) =x^T \Sigma ^{-1} y \)と置いた時、 \(d_{\Sigma} (x,y)^2 = \|x \| ^2 -2(x,y) +\|y \| ^2 \)と書けることから従います。
上の定義で使われる事は実はあまりなくて、以下のような定義が広く使われます。
多変量正規分布\(\mathcal{N} (\mu , \Sigma ) \)からサンプルされたデータ\(x\)に対して、
$$\begin{eqnarray}
d_{\Sigma } (x) = (x-\mu )^T \Sigma ^{-1}(x-\mu )
\end{eqnarray}$$
と定義されます。確率分布\( \mathcal{N}(\mu , \Sigma ) \)と、サンプルされたデータの距離を測っているイメージです。確率分布は平均値\( \mu \)で値を代表させています。
m次元正規分布からデータをサンプルしている場合、マハラノビス距離は、自由度mのカイ二乗分布に従います。1
カイ二乗分布の95%点\( \alpha \)などを閾値にして、
$$\begin{eqnarray}
\alpha < (x-\mu )^T \Sigma ^{-1}(x-\mu )
\end{eqnarray}$$
のとき、x を異常値と判定します。
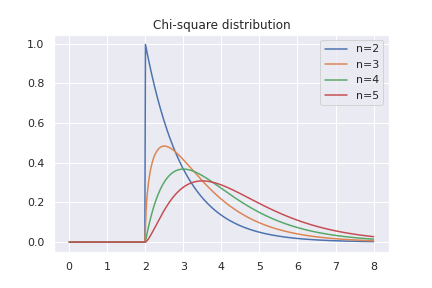
自由度mのカイ二乗分布は、期待値m分散2m なので、データの次元が大きくなると、閾値が大きくなります。この事から、次元が大きくなると、データが分布から外れる事に対して寛容になっていきます。特に、ある成分だけ変な値、というデータを異常と判定しにくくなります。
実際に、カイ二乗分布のグラフを描いてみると、自由度nが大きくなった時に、値が大きい方向の裾野が太くなっていくのが分かります。
実データに対するマハラノビス距離
実データでは、正規分布のパラメーター\( (\mu, \Sigma ) \)の正確な値は分かりません。
そこで、正規分布のパラメーターは最尤推定で求める事にします。2M次元のデータがN個あるとしましょう。最尤推定量は以下のように求まります。
$$\begin{eqnarray}
\hat{ \mu} &=& \sum x_i /N \\
\hat{\Sigma} &=& \sum (x_i -\hat{\mu } )^T (x_i -\hat{\mu } ) /N
\end{eqnarray}$$
実データでマハラノビス距離を測るには、初めに安定したデータから正規分布のパラメーターを推定する必要があります。推定したパラメーターを用いたマハラノビス距離もカイ二乗分布に従う事が知られています。3
$$\begin{eqnarray}
d_{\hat{\Sigma }} =(x-\hat{ \mu })^T \hat{\Sigma }^{-1}(x-\hat{\mu } ) \sim \chi_{M} ^2
\end{eqnarray}$$
カイ二乗分布に従うので、95%点などを閾値にして、異常か正常化を区別することが出来ます。初めのマハラノビス距離の節でも書いた事ですが、データの次元Mが大きくなると、外れ値に対して寛容になる事に注意しましょう。
以下でpythonを使って実験してみます。
マハラノビス距離による異常検知
初めに、データを適当に生成して、推定値から計算したマハラノビス距離がカイ二乗分布に従う事を見ます。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
import pandas as pd
import scipy.stats as stats
!pip install japanize-matplotlib
import japanize_matplotlib
#データの生成
N=10000
M=10
np.random.seed(1)
sig=np.random.randn(M)
Sig = sig.reshape(-1,1)@sig.reshape(1,-1) +np.eye(M)
np.random.seed(2)
mu = np.random.randn(M)
X=np.random.multivariate_normal(mean=mu, cov=Sig,size=N)
#計算用の関数
def est(x):
x=np.array(x)
mu = np.mean(x)
N=x.shape[0]
M=x.shape[1]
y=(x-mu).reshape(N,M)
Sig =y.T @y /N
return mu, Sig
def mah(mu,Sig, y):
y=np.array(y).reshape(1,-1)
M=y.shape[1]
distance = (y-mu) @np.linalg.inv(Sig)@(y-mu).T
return distance
#計算してグラフを描く
dist=np.array([])
mu,sig = est(X)
for i in range(N):
y=X[i]
dist=np.append(dist,mah(mu,sig,y ))
sns.distplot(dist, label="Mahalanobis")
sns.distplot(stats.chi2.rvs(M,size=N), label="chi^2")
plt.legend()
plt.title("マハラノビス距離はカイ二乗分布に従う")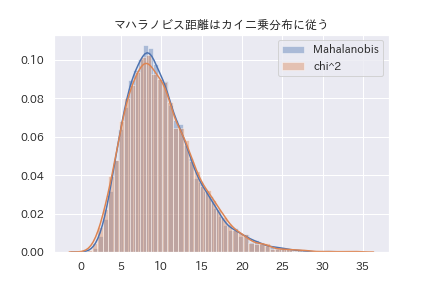
10次元の正規分布に従うデータから作ったマハラノビス距離は自由度10のカイ二乗分布に従っている事が分かります。
自由度10の場合は、18.4くらいが95%点になります。一方で、自由度2だと、6.0くらいが95%点です。データの次元が大きいと、異常の判別が寛容になる事が分かります。4
次に、適当なデータを作成して、異常かどうか判断します。
mu_1 = mu+10
mu_2=mu
mu_2[0]=mu[0]+10
x_1 = np.random.multivariate_normal(mean=mu_1,cov=sig,size=1)
x_2 = np.random.multivariate_normal(mean=mu_2,cov=sig,size=1)
mah(mu,sig,x_1)
#array([[991.73025515]])
mah(mu,sig,x_2)
#array([[11.8519134]])\(x_1 \)は、正常と思っているデータから、平均値の全ての成分が10ずれているデータです。\(x_2 \)は、データの平均値の第一成分だけが、10ずれているのがデータです。
分散が1程度のデータを使っているので、2つとも異常値な気もします。しかし、(x_1 \)はマハラノビス距離が991に対して、\(x_2 \)は11です。
閾値として、カイ二乗分布の95%点を採用していると、\(x_2 \)は正常な値として処理します。
マハラノビス距離を使う時は、気を付けないといけないポイントです。
まとめ
- マハラノビス距離を定義した
- マハラノビス距離はカイ二乗分布に従う
- 推定値でのマハラノビス距離を定義した
- マハラノビス距離はカイ二乗分布に従うので、仮説検定で異常か正常か決めれる
- データの次元が大きい時は、異常の判断がゆるくなる
- カイ二乗分布の記事で解説してます。
- 細かな計算は多変量正規分布の記事を見てください。
- N>>Mの場合です。詳しくは別の記事で計算します。これはホテリングのT2理論で出てくる値と同じです。
- 閾値を手動で決めても良いですが、統計的な根拠は薄くなります。
