
今回の記事では、Python でディープニューラルネットワークモデルを1から実装します。つまり、ニューラルネットワークの隠れ層の数を好きに弄れるモデル1を作ります。Python でニューラルネットワークを実装する記事の続きモノなので、とりあえず深いニューラルネットワークモデル(ディープニューラルネットワーク)を作ります。
ニューラルネットワークを知らない人はこちらの記事をどうぞ。

記事に出てくる実装用のコードは以下の本を参考にしています。コードだけならネットで無料で見れるので、試してみてください。
https://github.com/oreilly-japan/deep-learning-from-scratch

記事で使っているソースコードはgithub に置いてあります。
https://github.com/msamunetogetoge
ディープニューラルネットワークとは
今回の記事でやりたいことを説明します。
ニューラルネットワークは入力層、隠れ層、出力層の3種類の層で出来ています。入力層は与えられたデータ形状から、大きさが決まっています。出力層も。予測したいデータの種類で大きさが決まっています。隠れ層だけが大きさを自由に変える事が出来ます。勿論、隠れ層を増やすことも出来ます。隠れ層が増えると、パラメーターの数が増えるので、モデルの表現力が”一応”高くなります。
理論的には、層の数と層のノードの数をそれぞれ決めてやれば勝手に行列やベクトルの大きさが決まるので、特にやることはありません。
python で実装という話になると、よく使う行列を掛けてベクトルを足す、という操作とその微分をクラスとして準備する必要があります。必要なパーツは全て前回までの記事にあるので、それをクラス化して、新たにクラスでまとめるだけです。
モデルとしては、出力にはsoftmax 関数を使い、誤差関数はクロスエントロピーを使います。2 また、活性化関数にはreluを使います。パラメーターの更新法は単純な勾配法です。
ニューラルネットワークに登場する関数のクラス化
初めに、活性化関数に使うrelu と出力に使うsoftmax関数、損失関数をクラス化します。ある層A の勾配の計算は、連鎖律から (Aより出力側全体の勾配)×(A部分の勾配 ) となることに注意しましょう。なので、順方向にデータを流す場合はデータが入力として入ってきます。微分を考える時は、出力側から、勾配が入ってきます。 意味不明な場合は以下の記事をどうぞ。
登場する関数をクラスとして保持するコードを書きます。 forward が関数を作用させる計算で、backwardが微分の計算です。
class Relu:
def __init__(self):
self.mask=None
def forward(self,x):
self.mask = (x<= 0) #データにある0以下の数字の場所の目印 , relu(x) =x (x>=0), 0 (x<0)
out= x.copy()
self.out = out
out[self.mask]=0
return out
def backward(self, dout):
dout[self.mask ] = 0
dx = dout
return dx
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None
self.x = None
def forward(self, x, t):
self.t =t
self.y=softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size= self.t.shape[0]
dx = (self.y -self.t)/batch_size
return dx
次に、行列を掛けてベクトルを足す操作をクラス化します。数学ではこのような操作はアファイン変換とか線形変換とか呼びます。クラス名の由来はそういう事です。コードを書きます。
class Affine:
def __init__(self, W, b):
self.W=W
self.b=b
self.x=None
self.dW=None
self.db=None
def forward(self ,x):
self.x = x
out =np.dot(x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T , dout)
self.db = np.sum(dout, axis=0)
return dxこれで必要な関数の準備が出来ました。次は、ニューラルネットワークモデルを作るクラスを書きます。
デイープニューラルネットワークの実装
作るクラスが持っていてほしい機能は、以下です。
- アファイン変換でデータの形を順々に変える。
- reluで活性化する。
- softmax 関数予測値を得てる。
- 誤差関数を計算 する。
- 各層、パラメーターの勾配の計算をする。
欲しい機能を持ったクラスを作ります。
import numpy as np
from collections import OrderedDict
class Sequential:
def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01):
# 重みの初期化, 隠れ層の大きさと数に応じた行列とベクトルの生成
self.n = len(hidden_size)
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size[0])
self.params['b1'] = np.zeros(hidden_size[0])
for i in np.arange(start=2, stop = self.n +1 ) :
self.params['W'+str(i)] = weight_init_std * np.random.randn(hidden_size[i-2], hidden_size[i-1])
self.params['b'+str(i)] = np.zeros(hidden_size[i-1])
self.params['W'+str(self.n+1)] = weight_init_std * np.random.randn(hidden_size[self.n -1 ], output_size)
self.params['b'+str(self.n+1)] = np.zeros(output_size)
# レイヤの生成
self.layers = OrderedDict()
for i in np.arange(start = 1 , stop= self.n +1 ):
self.layers['Affine'+str(i)] = Affine(self.params['W'+str(i)], self.params['b'+str(i)])
self.layers['Relu'+str(i)] = Relu()
self.layers['Affine'+str(self.n +1 )] = Affine(self.params['W'+str(self.n +1 )],self.params['b'+str(self.n +1 )])
self.lastLayer = SoftmaxWithLoss()
def predict(self, x): #予測値の計算
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):# 誤差関数の計算x:入力データ, t:教師データ
y = self.predict(x)
return self.lastLayer.forward(y, t)
def accuracy(self, x, t):#正答率の計算
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def gradient(self, x, t): #勾配の計算 x:入力データ, t:教師データ
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 設定
grads = {}
for i in np.arange(start = 1 , stop = self.n +2):
grads['W'+str(i)], grads['b'+str(i)] = self.layers['Affine'+str(i)].dW, self.layers['Affine'+str(i)].db
return grads
このコードのポイントは、勾配や予測値の計算をするには各関数の出力や微分 out , dout を代入していくだけという所です。勾配の計算を行う時は、OrderedDict の順番を逆向きにすることで連鎖律(誤差逆伝搬法)を再現しています。
ディープニューラルネットワークの学習
Sequential クラスでディープニューラルネットワークモデルを作り、FASHON MNIST のデータを学習させてみましょう。計算が重くなりすぎるのが嫌なので、隠れ層は2つにしておきます。
network =Sequential(input_size=784, hidden_size=[128,128] , output_size=10)
#hidden_size はPCの性能で適当に変えてください。
train_size = train_images.shape[0]
batch_size = 1000
iter_num = 10000
learning_rate =0.1
loss_list = []
train_acc_list = []
test_acc_list = []
grad_list = []
iter_per_epoch = 100
for i in np.arange(iter_num):
batch_mask = np.random.choice(train_size , batch_size)
x_batch = train_images[batch_mask]
t_batch = train_labels[batch_mask]
grad = network.gradient(x_batch, t_batch)
for key in network.params.keys():
network.params[key] -= learning_rate * grad[key]
if i % iter_per_epoch == 0:
loss = network.loss(x_batch, t_batch)
loss_list.append(loss)
train_acc = network.accuracy(train_images, train_labels)
test_acc = network.accuracy(test_images, test_labels)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))
print("Finish Caluculation")
#学習結果の描画
x = np.arange(len(train_acc_list))
plt.figure(figsize=(13,3))
plt.subplot(1,2,1)
plt.plot(x, train_acc_list, label='Train Acc')
plt.plot(x, test_acc_list, label='Test Acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.title("Train Acc VS Test Acc")
plt.subplot(1,2,2)
plt.plot(x, loss_list, label=" Error")
plt.xlabel("epochs")
plt.legend()
plt.title("Value Of Loss Function")管理人の実行結果では、トレーニングデータで92%, テストデータで88%の正解率に至りました。
結果のグラフを描いてみます。
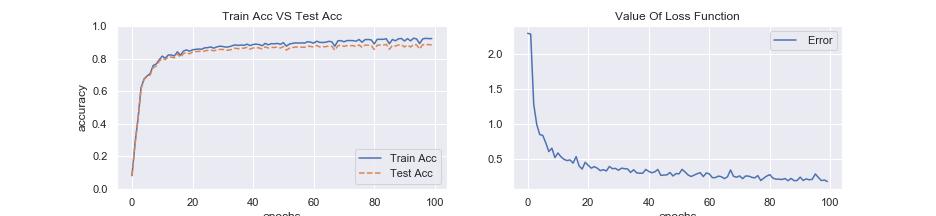
グラフを見ると、過学習してる感じです。学習の回数を増やせば、トレーニングの方は正解率が上がりますが、テストの方は上がりません。隠れ層が一層だけの場合では、テスト用データの正答率が86%くらいだったので、一応良いモデルになっています。実際にデータを弄る時でも、単純に層を深くするだけでは、劇的に良いモデルになることは殆どありません。何故でしょうか?
それは、行列を掛けてベクトルを足すという単純な操作だけでは、画像データの特徴を捉えきることが出来ないためです。つまり、もっと複雑なモデルを作る必要があります。偉大な先人が色々考えてくれているので、次回は少しだけ複雑なモデルを実装してみます。
まとめ
・前回の記事の続きで、隠れ層を増やせるニューラルネットワークモデルを実装した。
・アファイン変換だけのモデルでは、画像という複雑な対象を説明しきる事は出来ない。

