
自然言語処理では、人間が使う言葉をコンピューターに理解させるための定番の作業や手法があります。定番の作業はword2vecと呼ばれています。文章に前処理をしてモデルに学習させるまでの流れを解説 1 します。
最後に不思議の国のアリスのテキストを使って、素朴なCBOW( Countinuous Bag-of-Words )モデルで文章の穴埋めをします。
word2vec
word2vecと呼ばれる手法を解説します。色々な意味で使われるのですが、前処理としてほぼ必ず行われる手法です。python での実装コードと共に解説します。やる事は単純で、各単語や文字に対して固有の数字を与えるだけです。日本語だと少し大変なので、英語を扱うと想定してコードを書いてみます。
普段目にする文章は大文字と小文字が混じった状態になっています。普通は大文字と小文字は区別せず使います。また、英単語の場合は半角スペースを目印に単語を区切るのですが、文章の最後のドット 2 はそうなっていないので、半角スペースを挿入します。
text ="Masamune say that I am cute Hedgehog. I say that you are so cute."
text=text.lower()#大文字を小文字に変換
text=text.replace(".", " .")#. の前に半角スペースを挿入
print(text)
#'masamune say that i am cute hedgehog . i say that you are so cute .'
words = text.split(" ")#半角スペースで文章を区切る
print(words)
#['masamune', 'say', 'that', 'i', 'am', 'cute', 'hedgehog', '.', 'i', 'say', 'that', 'you', 'are', 'so', 'cute', '.']文章を単語に分けたら、単語に固有の数字を与えます。大体の文章はダブりの単語があるのでそれを削除しなくてはいけません。また、文字から数字を得るだけでなくて数字から文字を得る必要があります。
vocab = sorted(set(words))#ダブりを削除した単語のリスト
print(vocab)
print ('{} unique characters'.format(len(vocab)))
#['.', 'am', 'are', 'cute', 'hedgehog', 'i', 'masamune', 'say', 'so', 'that', 'you']
#11 unique characters
import numpy as np
char2idx = {u:i for i, u in enumerate(vocab)}#辞書形式で単語→文字の対応を保存
idx2char = np.array(vocab)
print(char2idx["masamune)
print(idx2char[6])
# 6
#'masamune'
text_as_int = np.array([char2idx for c in words])#文章を数字で表現
print(text_as_int)
#[ 6 7 9 5 1 3 4 0 5 7 9 10 2 8 3 0]単語を数字に変換できました。この数字の列のまま使う事もありますが、one hot encoding することが多いです。
単語と数字の対応がついている大きいデータセットがあれば、この処理は殆どいらなくなります。そのようなデータセットが既に作られています。例えばPTB(pen treebank ) があります。python では
from dataset import ptbでインポートできます。こんな感じで前処理したら次はモデルに渡して学習していきます。
モデルに学習させるための準備
単語を当てる問題では、アプローチが2つあります。
- 連続した単語を入力して、次に来る単語を予測する。(N -gram)
- 一か所だけ空白の文の一部を与えて、空白に入る単語を予測する。(CBOW)
- ある単語の周りに来る単語を予測する。(N-skip gram)
前者2つをコード付きで解説します。
初めに、連続した単語を予測させる場合です。初めの3単語を与えて次の単語を予測させる場合を考えます。
window_size=3
y = text_as_int[window_size:] #答えの単語を生成
x=[] #入力データの入れ物
for idx in range(window_size, len(text_as_int)):#答えの単語の場所の目印
X=[]
for t in range(idx-window_size, idx): #答えの3つ前までの単語をリストに追加する
X.append(text_as_int[t])
x.append(X)
for i in range(0,len(x)):
print(idx2char[x[i]])
print(idx2char[y[i]])
#['masamune' 'say' 'that'] iとか出る次に、予測したい単語の前後2つの単語から、真ん中の単語を予測する場合を考えましょう。
前処理は以下のように実装出来ます。
window_size=2
y = text_as_int[window_size:-window_size] #答えの単語を生成
x=[] #入力データの入れ物
for idx in range(window_size, len(text_as_int)-window_size):#答えの単語の場所の目印
X=[]
for t in range(-window_size, window_size+1): #答えの周りの単語だけをリストに追加する
if t==0 :#答え単語はリストに追加しない
continue
X.append(text_as_int[idx + t])
x.append(X)
for i in range(0,len(x)):
print(idx2char[x[i]])
print(idx2char[y[i]])
#['masamune' 'say' 'i' 'am'] that とか出るCBOWモデル
虫食い状態の文章を完成させる(語弊がありますが)問題を解くモデルをCBOWモデルと呼びます。
モデルはシンプルで、入力層と中間層で学習して、softmax関数で出力するだけです。
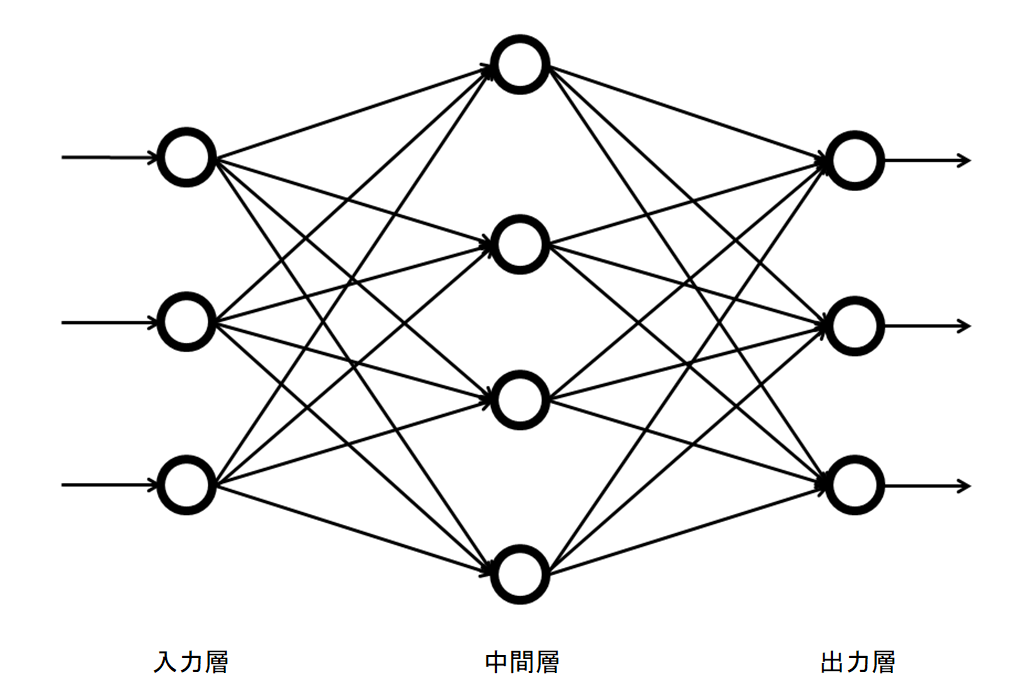
与えられるデータはone hot encoding されているので、入力層から中間層への行列の特定の行を抜き出すだけの演算になります。行列に単語の情報を埋め込むという意味で、中間層をEmbedding 層と呼んだりします。入力が3次元, 中間層が2次元の場合で確認してみましょう。
e1=np.array([1,0,0])
W=np.random.randn(3,2)
print(W)
#[[1 2]
#[3 4]
#[5 6]]
np.dot(e1,W)
#array([1, 2]) [細かい注意]
与えるデータは、one hot encodingされているので、次元が追加されます。例えば、単語の周り2単語を入力として用いる場合は、元は(全単語数-2, 2) 3 の形の入力データですが、one hot encoding すると (全単語数-2, 2, 単語の種類) という形になります。
このデータをCBOWに渡すと、中間層でも(中間層のノード数, 単語の種類) という2次元データ出てきます。最終的にはsoftmaxやsigmoid 関数で出力したいので、単語の種類部分の次元を消す必要があります。単語の種類の次元について平均を取って消去することが多いです。
CBOWによる文章の穴埋め
以下の事をやってみたいと思います。
- 適当な文章を元にCBOWモデルを学習する。
- 文章の穴を埋めてもらう。
英語で著作権フリーっぽい作品は鏡の国のアリスくらいしか思いつかないので、それでやってみます。
最初の前書きみたいなものは削除して、モデルに渡します。単純なモデルで工夫を一切していないので、汎化性能は0です。あまり実用性はありませんが、コードを載せておきます。テキストは, http://www.gutenberg.org/files/11/11-0.txt から取ってきます。
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
from keras.preprocessing import sequence
from keras.utils import np_utils
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Lambda, Embedding
import tensorflow.keras.backend as K
import numpy as np
import os
text = open('alice.txt', 'rb').read().decode(encoding='utf-8')
text=text.lower()
text=text.replace(".", " .")
text=text.replace("\n", " ")
words = text.split(" ")
vocab = sorted(set(words))
char2idx = {u:i for i, u in enumerate(vocab)}
idx2char = np.array(vocab)
text_as_int = np.array([char2idx for c in words])
vocab_size = len(vocab)
embed_size = 512
window_size = 4
batch_size = 64
epochs = 50
y = text_as_int[window_size:-window_size]
x=[]
for idx in range(window_size, len(text_as_int)-window_size):
X=[]
for t in range(-window_size, window_size+1):
if t==0 :
continue
X.append(text_as_int[idx + t])
x.append(X)
x_train = sequence.pad_sequences(x, maxlen=window_size*2)
y_train = np_utils.to_categorical(y, vocab_size)
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=embed_size,
embeddings_initializer='glorot_uniform',
input_length=window_size*2))
model.add(Lambda(lambda x: K.mean(x, axis=1), output_shape=(embed_size,)))
model.add(Dense(vocab_size,
kernel_initializer='glorot_uniform',
activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer="adam")
hist = model.fit(x_train, y_train,
batch_size= batch_size,
epochs= epochs,
validation_split=0.2)これを実行すると凄い過学習したモデルが出来ます。
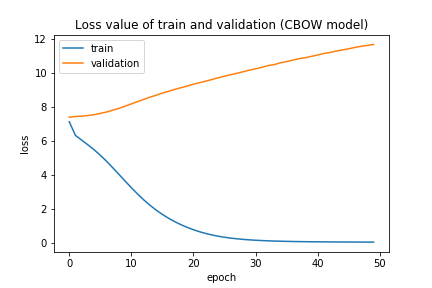
これでは新しいデータには全く対応できませんが、工夫無しではこんなものです。別の記事で改良版や、別の手法を解説したいと思います。
最後に、不思議の国のアリスで有名な文章に入る言葉を埋めてもらって4終わりにします。
Oh, ’tis love, ’tis love that makes the world go round.
これの真ん中あたりのlove を埋めてもらいます。
x=", ‘tis love , ‘tis that makes the world go"
x=x.split(" ")
x_test = np.array([char2idx[char] for char in x])
y=idx2char[np.argmax(model.predict(x_test.reshape(1,-1)) )]
print(x_test)
print(y)
#[',', '‘tis', 'love', ',', '‘tis', 'that', 'makes', 'the', 'world', 'go']
#love
不思議の国のアリス再現機が出来ました。
人間失格をN-gram のやり方でRNNモデルに学習させる記事があるので、興味がある方はどうぞ。こちらは少しだけ汎用性があります。

まとめ
- 自然言語処理のスタートはword2vec
- モデルは色々ある
- 素朴なCBOWモデルは過学習バリバリで実用に耐えるものではない
- 不思議の国のアリスの有名な一節は再現できる

