
世の中では機械学習が最早当たり前の技術として使われています。Society 5.0 ではクラウド上のデータをAIが処理して人間に便利な世の中を作ってくれるそうです。クラウド上で機械学習をするわけですが、全ての処理をクラウド上で行うのは不安ですよね。
例えば顧客の名前や年齢、性別などのデータから何らかの判断を下す材料をディープラーニングで得る時、顧客のデータをそのままクラウドに載せる人間はあまりいないと思います。クラウド上で計算するのはどうでしょう?具体的には、色々なモデルをクラウドに置いておいて、重みの情報だけをクラウドからダウンロードするのです。これは前者よりは安全な気がします。
それは案外危ないよと言う記事です。元ネタの論文1は以下から読めます。
https://eprint.iacr.org/2017/715.pdf
使ったモデルの作成と学習のコードは以下に置いてます。
https://github.com/msamunetogetoge/masamune
ニューラルネットワークの基本式と特徴量の復元
全ての基本である、ニューラルネットワークの構造を復習しましょう。
ニューラルネットワークとは、全結合層を何層も重ねたモデルでした。全結合層では以下の演算を行います。
$$\begin{eqnarray}
f(x) =Wx+b
\end{eqnarray}$$
ただし、\(x \)が層への入力、\(W \)は重み行列、\(b\)がバイアスベクトルです。簡単の為に、入力層と出力層のみからなるニューラルネットワークを考えましょう。
\(x \)に対応するラベルを\(y \)として、 損失関数をMSEとすると、loss は以下のようになります。
$$\begin{eqnarray}
L =\| y- (Wx+b) \| ^2
\end{eqnarray}$$
\( L \)が小さくなるようにパラメーター\(W, b\)を更新するのがニューラルネットワークの教育方針でした。基本的に、パラメーターの更新は勾配法によります。
という訳で、勾配を計算してみましょう。誰でも計算できるよう、成分毎に計算してみます。
$$\begin{eqnarray}
\frac{\partial L}{\partial W_{ik} } =-2 (y_i – \sum_{l} (w_{il}x_l +b_i ) ) x_k
\end{eqnarray}$$
ただし、\(W_{ik} , x_{l}, y_{i} \)などは、行列とベクトルの成分を表しています。バイアスでの微分も計算しましょう。
$$\begin{eqnarray}
\frac{\partial L}{\partial b_{i} } = -2 (y_i – \sum_{l} (w_{il}x_l +b_i ) )
\end{eqnarray}$$
ちょっと待ってください。
$$\begin{eqnarray}
\frac{\partial L}{\partial W_{ik} } / \frac{\partial L}{\partial b_{i} } = x_k
\end{eqnarray}$$
です。単純なニューラルネットワークの場合だと、入力に最も近い層のパラメーターの微分から特徴量 \( x_i \)が復元出来てしまいました。モデルが訓練されていなくても、特徴量を抽出することが出来ます。
つまり、パラメーターの勾配が特徴量に関する情報を持っている2のです。
python での実装
過去に自作した単純なニューラルネットワークで、勾配情報から特徴量の情報を復元してみましょう。
fashon mnistのデータと、隠れ層が1つだけあるニューラルネットワークを使います。細かいコードはgithubで見てください。
network =TwoLayerNet(input_size=784, hidden_size=64 , output_size=10)
grads_list=[]
for i in range(10):
grads_list.append(network.gradient(train_images[0].reshape(1, 784), train_labels[i]))
for i in range(10):
im= grads_list[i]["W1"][:,0]/grads_list[i]["b1"][0]
im = im.reshape(28,28)
plt.subplot(1,10,1+i)
plt.imshow(im)
学習済みのモデルに対して。1番目の訓練データについての勾配を何個か計算し、プロットしています。\( W1 \)が重み行列で、\(b1 \)がバイアスです。

明らかに入力したデータを復元できています。一応正解の入力データも見てみます。
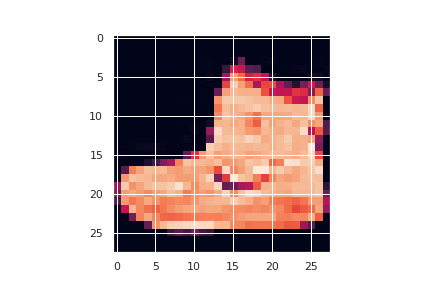
クラウドに何も考えずにデータを挙げるのは怖いって言うこと3ですね。
まとめ
- ニューラルネットワークの勾配には特徴量の情報が残っている
- 自作の簡単なニューラルネットワークでは、ほぼ100パーセント情報を復元できた

