
機械学習を齧ったことがある人なら、サポートベクトルマシンという名前は聞いたことがあると思います。線形分離可能なデータに関しては非常に強力であり、そのモデルの作り方から過学習しにくいという長所があります。
サポートベクトルマシンをカーネル化することで、線形分離不可能なデータも綺麗に分類できるようになります。初めからカーネルサポートベクトルマシンを考えておいて、カーネルを単位行列にすれば普通の(?)サポートベクトルマシンになります。
この記事では、サポートベクトルマシンの原理を解説します。その過程でサポートベクトルマシンがスパース性をもつ理由、サポートベクトルの意味、何故過学習しにくい理由を解説します。別の記事で、サポートベクトルマシンの幾何学的意味を解説します。
カーネル法の雰囲気を掴みたい方は以下の記事をどうぞ。

以下の2冊の本を参考にしています。解説してない部分がどうしても気になる方は自分で読んでみてください。
2値分類サポートベクトルマシンの為の誤差関数
2値分類問題を考えましょう。ラベルは\( \{1 , -1\} \)の2種類とします。カーネルK を使って、以下のようにモデルを考えましょう。
$$\begin{eqnarray}
f(x) =K \vec{\alpha}
\end{eqnarray} $$
回帰分析なら、二乗誤差を最小にすることでパラメーターを決めます。二乗誤差は次のような式になります。
$$\begin{eqnarray}
S(y, f(x) ) = ( y – f(x) )^2 = ( y f(x) -1 )^2
\end{eqnarray} $$
今はyの値は -1か+1だけです。一方で、\( \sum_j k(x_i ,x_j ) \alpha _j \) は連続な値を取ります。2乗誤差を使っていると、予測値が+1, -1から大きく外れたときに非常に大きな誤差になってしまいます。
実際のデータ解析では、外れ値と呼ばれるゴミが紛れているのが常です。2乗誤差では、ゴミの誤差が非常に大きくなり、モデルが思わしくない学習を進めてしまいます。
理想的には、次のような誤差でモデルを作りたいところです。
まず、出力は\( \pm 1 \)だけなので、出力 \( f(x) \)は符号だけ気にして、 \( {\rm sgn} (f(x) ) \) とします。そして、誤差は以下で定義します。
$$\begin{eqnarray}
r_{ {\rm misclass}}(y, f(x) ) = \left( \frac{ 1- y\cdot {\rm sgn }( f(x) )} {2} \right) ^2 =\frac{ 1-{\rm sgn }(y f(x) )}{2}
\end{eqnarray} $$
\( r_{\rm misclass} \)は、0か1の値しか取りません。正解か、不正解かにしか興味が無いという誤差関数です。この誤差が常に0ということは、全てのデータを正しく分類するという事です。
しかし、この誤差は階段状になっているので、数学的に扱うのは非常に面倒です。
これに近い挙動で、2乗誤差ほど変な値を拾わない誤差として、ヒンジ型誤差(ヒンジ関数)を使用します。以下のように定義される関数です。
$$\begin{eqnarray}
h(y, f(x) ) = \max \{ 0 , 1- yf(x) \}
\end{eqnarray} $$
それぞれの誤差関数を、横軸に \( yf(x) \)を取って書くと以下のようになります。
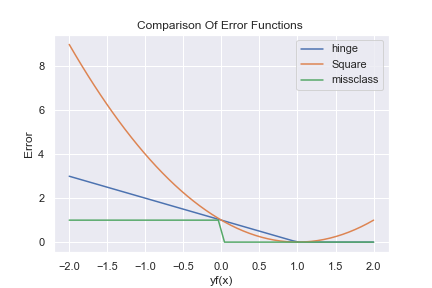
グラフにしてみると、2乗誤差がどんどん大きな値になっている事が分かります。それと比べるとヒンジ関数は小さい値を返しているので、2乗誤差と比べると外れ値に強い事が分かります。
サポートベクトルマシンの導出
サポートベクトルマシンは、ヒンジ関数による誤差と、\( L^2 \) 誤差を入れて以下のモデルから出てきます。
$$\begin{eqnarray}
f(x) &=&K \vec{\alpha} \\
L &=& \sum_i h(y_i , f(x_i ) ) + \frac{\lambda } {2} \alpha ^{T} K \alpha
\end{eqnarray} $$
Lを最小にする\( \alpha \)を求める問題を解くことで、サポートベクトルマシンが作れます。このままだと、サポートベクトルマシンの名前の由来が分からないので、少し問題を読み替えましょう。
Lの第一項を最小化するのはどういう事でしょうか。ヒンジ関数の値\( \xi _i = h( y_i f(x_i )) \)を次のように書き換えましょう。
$$\begin{eqnarray}
\xi _i &=& \min \left\{ \left \{ y_i f(x_i ) \geq 0 \right \} \cap \left \{ 1- y_i f(x_i ) \geq 0 \right \} \right \}
\end{eqnarray} $$
このように導入した変数をスラック変数と言います。すラック変数の値(ヒンジ関数の値)は、図形的な理解が出来ます。
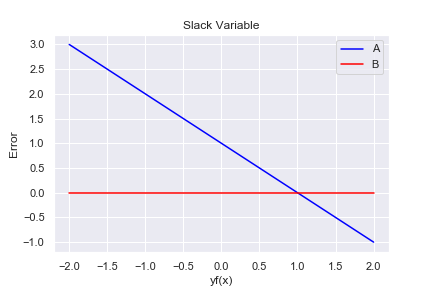
B: \( y_i f(x_i ) = 0 \)
青い線と赤い線で作られる左上側の三角形の辺上に、ヒンジ関数の値が集まっています。
このように書き直しておくことで、ラグランジュの未定乗数法1で今の最小値を探す問題が扱えます。
$$\begin{eqnarray}
L(\xi , \alpha ,\beta , \gamma ) =\sum \xi _i + \frac{\lambda}{2} \alpha ^{T} K\alpha -\sum \beta _i \xi _i – \sum \gamma _i (\xi _i – y_i f(x_i ) )
\end{eqnarray} $$
この形の問題の解が満たす条件が知られています。証明や詳しい条件は解説しないので、興味のある人は初めに挙げた本を読んでください。
[Karush-Kuhn-Tucker Theorem](K.K.T)
m個の不等式制約を持つ最適化問題
$$\begin{eqnarray}
\min f(x)\\
g_i (x) \leq 0
\end{eqnarray}$$
において、f,gは微分可能な凸関数とする。以下のラグランジュ関数が、正則条件を満たすとする。
$$\begin{eqnarray}
L(x,\lambda ) = f(x) + \sum g_i (x)
\end{eqnarray}$$
以下の条件を満たす \(x^{\ast} ,\lambda^{\ast} \)が存在することと、\( x^{\ast} \)が大域的な最適解である事は同値。
$$\begin{eqnarray}
\nabla _{x} L( x^{\ast} ,\lambda ^{\ast} ) = 0 \\
\lambda _i ^{\ast } \geq 0 , g_i (x ^{\ast} ) \leq 0 , \lambda _i ^{\ast } g(x_i ^{\ast})=0
\end{eqnarray}$$
K.K.Tが使える状況という事は認めましょう。大事なのは、\( \lambda _i ^{\ast } g(x_i ^{\ast})=0 \)の部分です。これを相補性条件と呼びます。ラグランジュの未定乗数か、条件式どちらかが必ず0になると言っています。これが何を意味しているか考えると、サポートベクトルマシンの名前の由来と、スパース性の謎が解けます。
サポートベクトルとスパース性
今考えているラグランジアンは以下でした。
$$\begin{eqnarray}
L(\xi , \alpha ,\beta , \gamma ) =\sum \xi _i + \frac{\lambda}{2} \alpha ^{T} K\alpha -\sum \beta _i \xi _i – \sum \gamma _i (\xi _i – y_i f(x_i ) )
\end{eqnarray} $$
これを\( \alpha \)で微分して0 とおきます。
$$\begin{eqnarray}
\nabla _{\alpha} L= \lambda K\alpha – K\hat{\gamma} =0
\end{eqnarray} $$
ただし、\( \hat{\gamma} _i = \gamma _i y_i \)です。この式から、全てのiについて
$$\begin{eqnarray}
\alpha _i = \frac{1} {\lambda _i}\gamma _i y_i
\end{eqnarray} $$
が分かります。
つまり、\( \gamma , \alpha \)は比例関係にあります。 \( \gamma =0 \)と\(\alpha =0 \)は同値です。
\(\alpha =0 \) という事は、相補性条件から、 \( \gamma =0 \) か、 \( \xi _i =1- y_i f(x_i) \) のどちらかが必ず成り立ちます。特に \(\alpha \neq 0 \) となるのは、 \( \xi _i =1- y_i f(x_i) \) が成り立つ場合 2 だけです。 \(\alpha \neq 0 \) となる \(x_i \)をサポートベクトルと呼びます。ラグランジュの未定乗数問題から、サポートベクトルが決定されます。
これらのサポートベクトルだけで、\( f(x) = \sum \alpha _i K(x_i , x) \) が構成されます。元のデータより少ない数のデータで予測値が計算されます。具体的には以下のようになります。
$$\begin{eqnarray}
f(x_i) = \sum_{j , \alpha _j \neq 0 } \alpha _j k(x_j , x_i)
\end{eqnarray} $$
サポートベクトルの数 \( \geq \) 元のデータの数なので、計算量が小さくなります。これが、サポートベクトルマシンのスパース性を生んでいます。 使うデータが少なくなるので、過学習も起きにくいという訳です。
サポートベクトルについての小話をします。
\( \xi _i =1- y_i f(x_i) \) というのは、ヒンジ関数の斜めの部分です。予測が上手くいっている時は、\( y_i f(x_i ) \geq 0\)となるので、サポートベクトルになるのは、予測が上手くいっていないベクトルか、予測が上手くいくかつ、\( \| f(x_i) \| \leq 1 \)となるベクトルだけです。サポートベクトルのうち、ヒンジの折れ曲がり付近にあるものは予測が上手くいっているベクトルで、斜めの遠くにあるサポートベクトルは予測が上手くいかないベクトルという訳です。
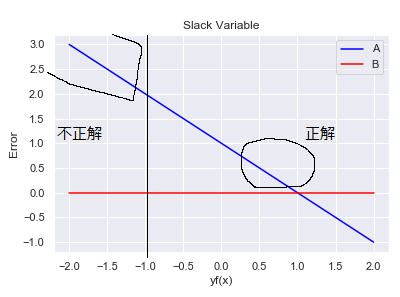
まとめ
・ヒンジ関数を誤差関数に使うとサポートベクトルマシンが出来る。
・サポートベクトルマシンにはスパース性がある。
・スパース性は、K.K.T.から出てくる。
・ヒンジ関数にベクトルの印をつけるとどれがサポートベクトルか分かる。
