
VAEとGANの説明をしてそれぞれで同じ画像を生成させてみます。生成された画像を比較して両者の特徴を比べてみます。
VAEとは
VAEは、variational autoencoder の略です。特徴としては、エンコーダーと呼ばれるモデルと、デコーダーと呼ばれるモデルを一列に並べる事です。また、エンコーダーの出力(デコーダーの入力)は、潜在空間と呼ばれます。例えば、以下のようにモデルを組みます。1

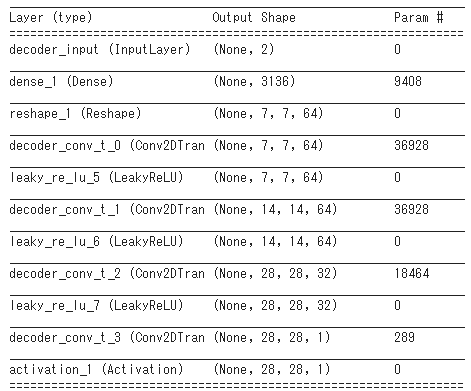
VAEでは、エンコーダーに入力したデータと、デコーダーが出力したデータが等しい事、潜在空間が正規分布に従う事を要請して、モデルを訓練します。エンコーダーを\(En \),デコーダーを\( De \)で表し、KLダイバージェンスを\(KL(- \| -) \), 平均二乗誤差を\(MSE \)で表すと、VAEの誤差関数は以下のように表されます。2
$$\begin{eqnarray}
L(x) =KL(En(x)\| \mathcal{N}(\mu,\Sigma )) +\alpha MSE(x-De(En(x)))
\end{eqnarray}$$
\( \mathcal{N}(\mu,\Sigma ) \)で多次元正規分布を表しています。ほとんどの場合は、標準正規分布を使います。 \(\alpha \)は適当な正の数で、潜在空間と、デコーダーの学習しやすさを決めます。3
KLダイバージェンスの項がある事で、デコーダーを通すと潜在空間の中に連続的にデータが分布しているようになります。
GANとは
GANは、 Generative Adversarial Networks の略です。2020年現在も、改良モデルが発表されています。GANの特徴は、generator と呼ばれるモデルと、 discriminator と呼ばれるモデル2つを同時に学習することです。4generator は、与えられたデータと同じ大きさのデータを返すモデルで、discriminatorは、与えられたデータが教師データそのものかgeneratorの出力かを判定するモデルです。以下のような模式図になります。
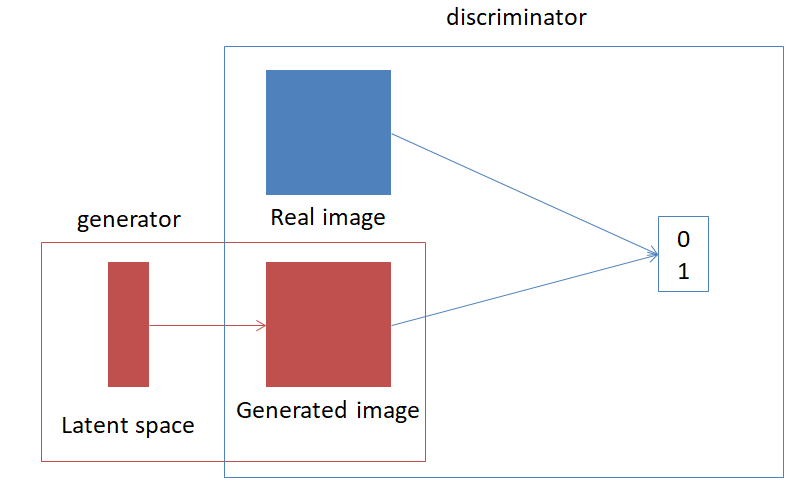
generator は、discriminator がgenerator が生成したデータを、教師データと間違えるように訓練し、discriminatorは、教師データか、generatorが生成したデータか見分けられるように訓練します。具体的には、クロスエントロピーを考えます。generator をG, discriminator をDで表します。
$$\begin{eqnarray}
L= E[\log (D(x) ] +E[\log(1-D(G(z))]
\end{eqnarray}$$
この損失関数を、Dについて最大化した後に、Gについて最小化するというのを繰り返す事で、GANの学習が進みます。
この最適解は、JSダイバージェンス(Jensen–Shannon Divergence )と大体同じ事が知られています。JSダイバージェンスは、KLダイバージェンスを本当の距離にした感じのもので、以下の式で定義されます。
$$\begin{eqnarray}
JS[p\|q] =\frac{1}{2} KL\left[ p \| \frac{p+q}{2} \right] +\frac{1}{2} KL\left[ q\| \frac{p+q}{2} \right]
\end{eqnarray}$$
詳しい話は、以下のサイトが分かりやすいです。

GAN自体には色々な問題がありますが、かなり鮮明な画像を生成できるという事で大きな注目を浴び、今でも人気のモデルになっています。
VAE,GANでの画像生成
VAEとGANでfashonmnist の画像を生成してみます。
初めに、VAEで生成します。
全種類の画像の生成は大変なので、靴とサンダルだけを学習して画像を生成させてみます。5初めに、お題の画像を与えて、エンコーダーと潜在空間を通してデコーダーで画像を取り出します。

上の画像が答えの画像で、下がVAEで生成した画像です。靴かサンダルかは分かりますが、靴の種類は殆ど分かりません。また、左から1,2番目の画像は靴とサンダルが逆になっている感じです。次に、潜在空間に適当にベクトルを渡して画像を生成してみます。
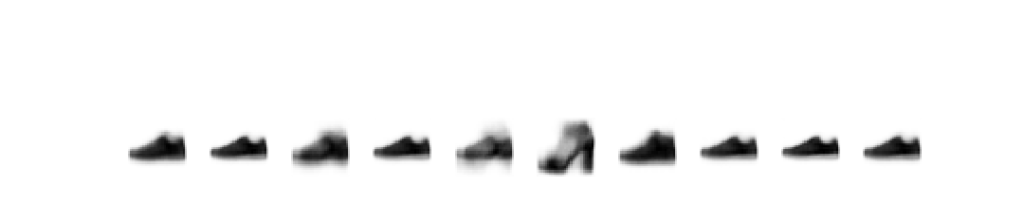
ぼやっとした感じの画像が生成されました。
GANでもfashonmnist の靴、サンダル画像を生成してみます。

靴に何か模様が入っています。VAEと比べて、画像がかなりはっきり書き込まれていて、靴にも種類があるのが分かります。
VAEとGANの比較
画像について
VAEとGANそれぞれで生成された画像を見ましたが、第一に感じるのが、VAEの画像は詳細が描かれていないという事だと思います。
VAEは、潜在空間の中に連続的に画像が存在する事が損失関数の形から要請されています。そのため、潜在空間の近い点同士の画像は似ていなくてはなりません。この時、2つの画像が似ているというのは、画像を行列だと思った時に、同じ成分の値が近いという事です。
その為、模様のような一つ一つの画像固有の部分を細かく学習することは、モデルに取って不利になるのです。6
学習について
今回の記事では触れていませんが、学習という面ではGANは問題が沢山あります。
以下のサイトの解説が詳しいです。
単純に考えて、2つのモデルがあって、それぞれのモデルを学習するときに、損失関数が学習度合の絶対値の指標にならないというのはやばい事だというのは伝わると思います。
また、モデルが複雑になるので学習コストがえげつないという事も、すぐに分かる問題として書いておきます。学習コストはさておき、問題を解決するための、GANの改良版が色々出ています。
以下のスライドにまとまっているので、読んでみると面白いと思います。
まとめ
- VAEについて説明した
- GANについて説明した
- VAEとGANで画像を生成した
- VAEとGANを比較した

