
ベイズ統計学の入り口である、ベイズの定理について解説し、具体例の計算をします。
統計学では、サイコロが2回連続で6が出ても、次に6が出る確率は1/6と計算されますが、ベイズの定理を考えると違う値になります。事前知識を参考にして未来を予測するという意味で、ベイズ統計学は人間的な推論を可能にする分野です。その雰囲気を、具体例の計算を通して掴むのが目標です。
詳しく知りたい方はこちらの本がオススメです。

機械学習に使う事を念頭に置いて書かれています。辛い計算もそれなりに行間を埋めてくれているのでやる気があれば高校生でも計算を追えます。そのまま使えるコードはついていませんが、疑似コードが書いてあるので、その通りに実装する事で、レベルアップを狙えます。
ベイズの定理
ベイズ統計学の要である、ベイズの定理を使って具体例を計算するのが目標です。確率の定義は適当に済ませたいと思います。
関数[mathjax]\( p \)が確率密度関数であるとは、以下の2条件を満たすことです。
[mathjax]$$\begin{eqnarray}
(&1&) 全てのxに対して0\leq p(x) \\
(&2&) \int p(x) dx =1
\end{eqnarray}$$
xは連続だと思っています。離散の場合は、積分を和に変えます。
関数[mathjax]\( p \)が確率質量関数であるとは、以下の2条件を満たすことです。
[mathjax]$$\begin{eqnarray}
(&1&) 全てのxに対して0\leq p(X) \\
(&2& ) \sum p(x) =1
\end{eqnarray}$$
ベイズの定理を述べる為に、言葉の定義をします。
x,y に対する確率密度関数p(x,y)に対して、
[mathjax]$$ \begin{eqnarray}
p(y) &=& \int_x p(x,y) dx \\
p(x|y) &=& \frac{p(x,y)}{p(y) }
\end{eqnarray}$$
とします。p(y)はyについての確率密度関数であり、p(x|y)はxについての確率密度関数です。p(x|y)のyは、xに対する確率密度関数を決めるパラメーターと解釈できます。
[mathjax]$$ \begin{eqnarray}
p(y|x) &=& \frac{p(x,y)}{p(x) }
\end{eqnarray}$$
に注意して、ベイズの定理を述べます。
ベイズの定理
$$ \begin{eqnarray}
p(x|y) &=& \frac{p(y|x)p(x )}{p(y) }
\end{eqnarray}$$
証明は定義を見ればすぐ分かると思います。p(x|y)がp(y|x)p(x)に比例するという事が大事です。p(y|x)はyについての確率ですが、そのパラメーターとして組み込まれたxがp(x|y)に影響を与えます。
ベイズの定理を用いた確率計算
ベイズの定理を使った事象の予測の大きな特徴は、事前に起こった現象を考慮して後の事象を予測する点です。言葉ではよく聞くけど、理解は出来てない人が多いんではないでしょうか。何個か計算して雰囲気を掴みましょう。二つ定番の例を計算してみましょう。一つ目は、赤玉白玉が入った袋から玉を取り出す問題です。二つ目は、正規分布の平均値の推定問題です。
赤玉2つ白玉1つが入った袋aと,赤玉1つ白玉3つが入った袋bがあるとします。袋から玉を取り出すという良くある奴を考えましょう。
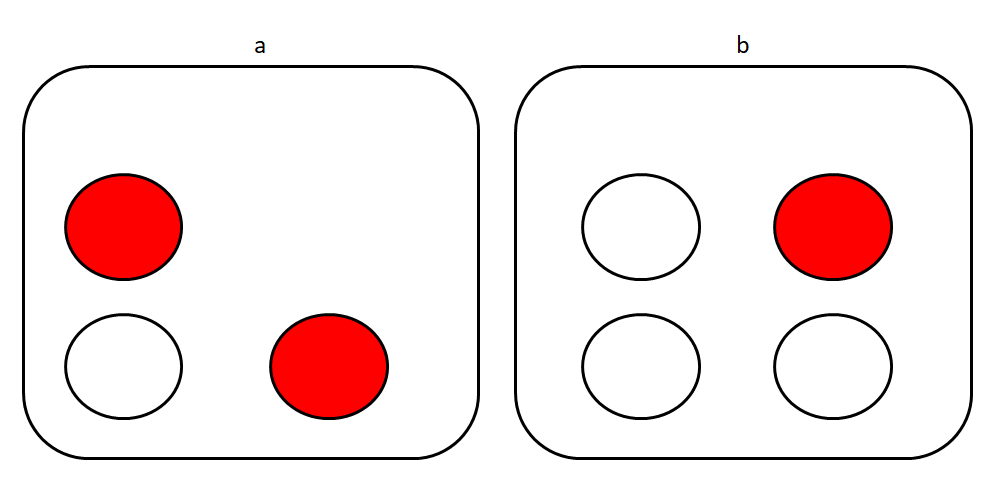
袋aから玉を取り出すという事象をx=a, 袋bから玉を取り出すという事象をx=b とします。赤色の玉を取り出す事象をy=r , 白色の玉を取り出すという事象をy=w とします。
$$\begin{eqnarray}
p(x=a)&=&1/2\\
p(x=b) &=&1/2
\end{eqnarray}$$
とします。袋aから取り出すことが分かっているときには、y=r, y=w となるそれぞれの確率は 以下のように書けます。
$$\begin{eqnarray}
p(y=r| x=a)&=&2/3\\
p(y=w| x=a) &=&1/3
\end{eqnarray}$$
公式に従って計算すると以下になります。
$$\begin{eqnarray}
p(y=r| x=a)&=& \frac{p(y=r, x=a)}{p(x=a) } \\
&=&(\frac{1}{2}\times \frac{2}{3} )/(1/2) \\
&=&2/3
\end{eqnarray}$$
今回の確率のように、p(x,y) = p(x)p(y)と、全体の確率がそれぞれの変数の確率の積に分解できるとき、xとyは独立であると言います。
順序がバラバラですが、p(x,y)は以下のように求める事も出来ます。
$$\begin{eqnarray}
p(y=r, x=a )&=& p(y=r| x=a) p(x=a) \\
&=& 2/3 \times 1/2 \\
&=& 1/3
\end{eqnarray}$$
p(y=r)はいくつでしょうか? 定義に沿って計算しましょう。
$$\begin{eqnarray}
p(y=r)&=& p(y=r, x=a) + p(y=r, x=b) \\
&=& 1/3 + 1/8 \\
&=&\frac{11}{24}
\end{eqnarray}$$
ここまでは、定義に慣れるためのお遊びでした。最後に、ベイズ統計学っぽいことをします。赤玉を取り出した時に、袋aから玉を取り出していた確率はいくらでしょうか?
$$\begin{eqnarray}
p(x=a | y=r )&=& \frac{p(y=r|x=a)p(x=a)}{p(y=r)} \\
&=& \frac{2/3 \times 1/2}{11/24} \\
&=& \frac{8}{11}
\end{eqnarray}$$
それでは、赤玉を取り出した時の、袋bである隔離はいくつでしょうか?
p(x|y)はxについての確率になっていることとを使うと以下のように計算出来ます。
$$\begin{eqnarray}
p(x=b | y=r )=1- p(x=a | y=r )=\frac{3}{8}
\end{eqnarray}$$
袋aには赤玉が割合沢山入っているので、赤が出たならaだろうという直感にあった答えになっています。
このような状況で、p(x)を事前分布、p(x|y=r)をデータy=rが観測された後の事後分布と言います。どちらも、xについての確率ですが、前提知識があるのとないのでは、全く違った確率になっている事に注意しましょう。
ベイズの定理を使おうと思うと、事前分布を手動で与える必要があります。 今回も、袋はどちらも平等に選ばれるだろうと勝手に仮定しました。
ベイズの定理を用いたパラメーター推定
正規分布について、ベイズの定理を使います。正規分布の性質を確認してい置きたい方はこちらの記事をどうぞ。

次に、正規分布に従っているデータから平均値[mathjax]\(\mu \)を推定します。 ただし、分散は既知とします。分散は知っているので、平均値についてだけ事前分布を設定すれば良いです。知っている確率分布は、
$$\begin{eqnarray}
p(x|\mu ) =\mathcal{N}(x|\mu, \lambda^{-1})
\end{eqnarray}$$
という状況なのですが、[mathjax]\( p(\mu) \)はどう設定したら良いでしょうか。答えは,どう設定しても良い。.になるのですが、計算した後も正規分布が出てきてくれるように [mathjax]\( p(\mu) \) も正規分布に従うとします。
$$\begin{eqnarray}
p( \mu ) =\mathcal{N}(\mu |m, \lambda_{\mu}^{-1})
\end{eqnarray}$$
[mathjax]\( m, \lambda_{\mu}^{-1 }\) は人間が決める必要のあるパラメーターです。今、ガウス分布に従うN個のデータ [mathjax]\( \mathbf{X} =\{ x_1, \cdots , x_N \} \)を観測したとして、事後分布を求めます。
$$\begin{eqnarray}
p(\mu|\mathbf{X} ) &=&\mathcal{N}(\mu |\hat{m}, \hat{\lambda}_{\mu}^{-1})\\
\hat{\lambda}_{\mu} &=& N\lambda + \lambda _{\mu} \\
\hat{m} &=& \frac{\lambda \sum x_n + \lambda _{\mu} m}{ \hat{\lambda}_{\mu} }
\end{eqnarray}$$
式を見ると、[mathjax]\( \hat{m} \)の式で、データが新しくなるたびに動くのは、[mathjax]\(\sum x_n \)の部分だけです。つまり、データを取ればとるほど、事前分布の影響は薄まり、新たに取得したデータの影響が濃くなっていくのです。悪く言えば、事前分布のパラメーターでは平均値の推定に関して、強い影響を与える事が出来ず、観測データで平均値を推定してしまうという事です。
詳しい計算は以下の記事に書いたので、自分で計算したい方は参考にしてみてください。

ベイズの定理による実験
最後の例の状況で、データを正規分布からサンプリングする場合を考えます。データが増えて行った時に、平均値がどう更新されていくか見てみましょう。
事前分布のパラメーターとして [mathjax]\( \lambda ,m, \lambda _{\mu} \) を使います。[mathjax]\( \mathcal{N} ( x |10, 1 ) \)からデータをサンプリングして、平均値がどのように更新されていくか調べてみます。上で作った平均値の更新式が上手く機能していれば、データを沢山学習させることで、10くらいに収束するグラフが得られるはずです。1[mathjax]\(\lambda , m , \lambda _{\mu} \) 数種類で実験してみます。x軸がデータの個数、y軸が更新された平均値です。
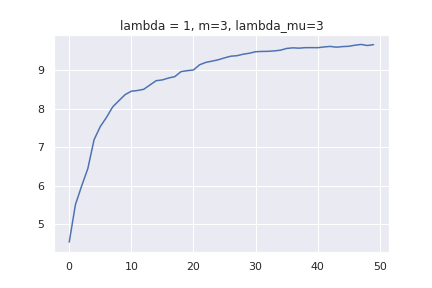
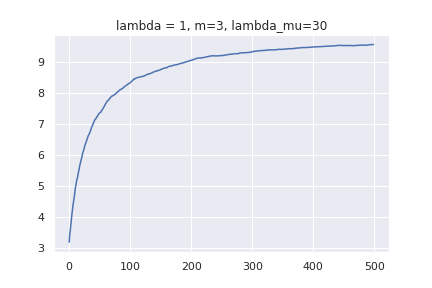
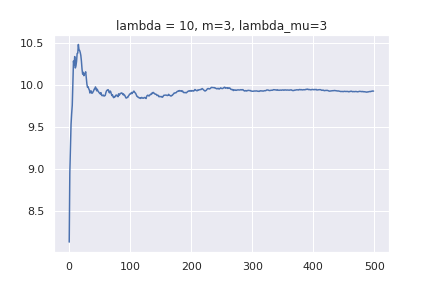
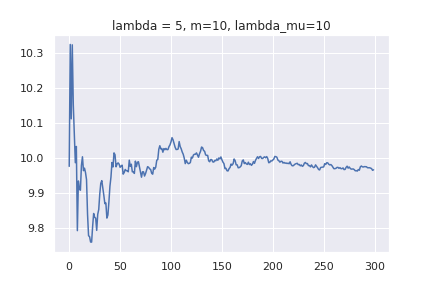
データ数=0のところでは、m の値になっていることが分かります。また、データを増やしていくと平均値が10くらいに収束しているのが分かります。注目してほしいのは、グラフの形の違いです。パラメーターによっては、x=50未満で10に到達するものもあれば、x=300個でもフラフラしているものがあります。事前分布が大して影響を与えないとしても、早く答えを得るためにはパラメーターの調整も必要だという事が分かります。
まとめ
- 確率の言葉を使って、ベイズの定理が証明できる。
- ベイズの定理を使うと、事前に得た情報から、普段は予測しにくい確率を求める事が出来る。
- 計算が大変なので、事前分布は慎重に選ぶ必要がある。
- 正規分布でそろえれば事後分布も正規分布になるが、データが増えると事前分布の情報は殆どなくなる。
- python で簡単に実験出来るのでやってみると楽しいです。別の記事でpython コードと、Google アカウントだけで無料で高性能PCを使う小技を紹介します。こちらをどうぞ。https://masamunetogetoge.com/colab
