
機械学習のタスクをこなすとき、損失関数を自分で定義したい事があります。そのような時、tensorflowには自分で定義した損失関数を使う機能があります。1
記事で使っているソースコードはgithub に置いてあります。
https://github.com/msamunetogetoge
Custom Loss Function の説明
オリジナルの損失関数(custom loss function )は、実際の値(y_val)と、予測値(y_pred )を受け取って、tensor を返す関数として定義します。
def custom_loss(y_val, y_pred):
"""
名前はなんでも良い
loss= 何らからの計算
"""
return loss注意する事は、tensorflowの中での演算は、tensorflow 独自のtensor というオブジェクトで行われる事です。そして、custom_loss(a,b)のa部分に真のデータが入り、b部分に予測値が入るようにすることです。
y_val はpandas やnumpy の型で入力されるが、y_predはtensor として与えられる、といった状況が起こり得ます。しかし、tensor とnumpy は互換性があり、pandas とnumpy は互換性があるので、あまり気にする必要がありません。また、コードの中でcustom_loss が呼ばれるのはmodel.fit ()の中なので、y_pred もy_val もtensor に変換されます。
Tensorについての補足
tensor の扱いついて、簡単に説明しておきます。
tensor には、値、データの形、dtype が保存されています。
import tensorflow as tf
import numpy as np
x=tf.constant(1.0)
print(x)
#tf.Tensor(1.0, shape=(), dtype=float32)tensor とnumpy.arrayを用意して、特に指定せずに演算を行うと、tensorに変換されます。
y=tf.constant([1.0,2.0])
z=np.array([3,3])
y+z
#<tf.Tensor: shape=(2,), dtype=float32, numpy=array([4., 5.], dtype=float32)>明示的にnumpy で計算したい時は、tensor からnumpy へ、.numpy()で変換できます。2
x=tf.constant(1.0)
print(x)
#tf.Tensor(1.0, shape=(), dtype=float32)
print(x.numpy())
#1.0pandas とtensor で何も考えずに演算を行うと、pandas object が出て来ます。しかし、tensorflow の演算を明示的に使うと。tensor が返ってきます。
x=pd.DataFrame(np.random.randn(100).reshape(-1,10))
y=tf.ones_like(x)
print(type(x))
#<class 'pandas.core.frame.DataFrame'>
print(type(y))
#<class 'tensorflow.python.framework.ops.EagerTensor'>
z=x-y
print(type(z))
#<class 'pandas.core.frame.DataFrame'>
w=tf.reduce_mean(z)
print(type(w))
#<class 'tensorflow.python.framework.ops.EagerTensor'>詳しくは公式サイトの説明を見ると良いです。

Custom Loss Function を作って使ってみる
custom loss function を使って、モデルを学習してみます。全体のコードはgithubに置いてあります。
tensorflow のサイトにある回帰の問題を使います。車の重さや構造、生産国の情報から、車の燃費(MPG)を予測する問題です。
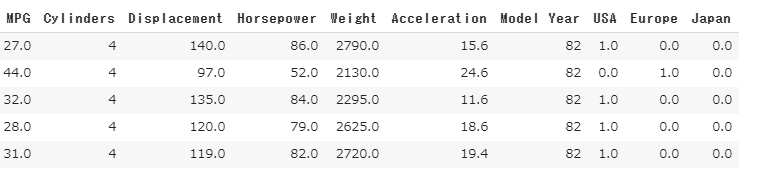
custom loss function をどうするかという問題がありますが、平均二乗誤差の3乗バージョンを損失関数にしてみます。
つまり、
$$\begin{eqnarray}
loss = \frac{1}{N} |y_{val} – y_{pred} | ^3
\end{eqnarray}$$
という事です。
custom_loss は、kerasを使う場合は以下のように書きます。
def custom_loss(y_val, y_pred):
loss=tf.reduce_mean(tf.math.abs((y_val - y_pred)**3))
return loss
大事なのは、custom_loss(a,b)のa部分に真のデータが入り、b部分に予測値が入るようにすることです。
model は以下のように書きます。3
def build_model():
model = tf.keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss=custom_loss,
optimizer=optimizer,
metrics=["mae"])
return model
model= build_model()
EPOCHS = 1000
history = model.fit(
normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2, verbose=1)model.compileの部分で、loss= に自分で定義した損失関数を入れます。比較の為にmaeがどうなるか見たいので、metrics に”mae”を指定しています。4
学習の様子をグラフに描くと以下のようになります。
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Absolute Error [MPG]')
plt.plot(hist['epoch'], hist['mae'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_mae'],
label = 'Val Error')
plt.ylim([0,10])
plt.legend()
plt.savefig("mae_loss.png")
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Custom loss [$MPG^2$]')
plt.plot(hist['epoch'], hist['loss'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_loss'],
label = 'Val Error')
plt.ylim([0,100])
plt.legend()
plt.savefig("custom_loss.png")
plt.show()
plot_history(history)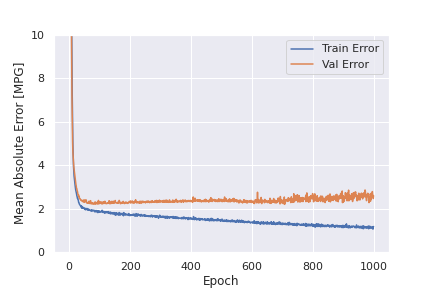
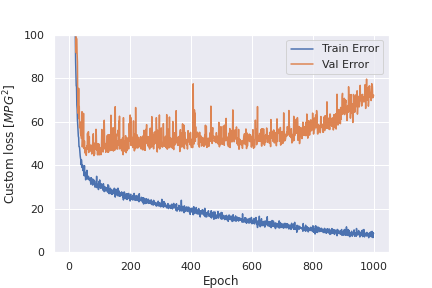
model.history に学習結果が保存されているわけですが、metrics にmaeを入れていたので、maeも入っています。custom_lossは、”loss”や”val_loss”として格納されています。
まとめ
- 自作の損失関数(custom loss)の作り方を説明した
- tensorflow 固有のオブジェクト tensor について説明した
- 実装方法を説明し、実際に動かした
- tf custom loss とか調べると解説の記事が出て来ます。
- tensorflow には、graph mode とeager execution mode があり、graph mode の時は.numpy()で値を取りだすことが出来ません。tensor flow 2.0からは、eager execution modeがデフォルトなので、tensorflowだけで作業する分には気にする必要はありません。しかし、keras でmodel を作る時、特に、model.fit()の中ではgraph mode になるようです。graph mode では、リストを渡して欲しい部分を取り出すという操作が出来なかったりするので注意が必要です。
- 実際にモデルを学習させたい人は、github のコードを使ってください。
- loss でcustom_lossを指定しているので、学習に使われる損失関数はcustom_lossです。

