
データのバックグラウンドが違い、一つの確率分布ではデータを近似できないことが多々あります。例えば、何かの寸法を計測結果がふた山の分布になってしまう場合などです。その時は、いくつかの確率分布を足し合わせてふた山のモデルを再現することになります。モデルのパラメーターの決める手法として、 EMアルゴリズム と呼ばれるものがあります。この記事では、EMアルゴリズムの原理を解説します。参考文献は3冊くらいあります。



混合正規分布
一番身近な正規分布を例に取りたいと思います。多次元正規分布を使いますが、定義を忘れた方は以下の記事をどうぞ。

混合正規分布(Gaussian Mixture Model , GMM)というのは、\(K \)個の正規分布\( \mathcal{N} \left( x| \mu _k , \Sigma _k \right) \)と、混合割合\( \sum_{k=1} ^{K} \pi _k =1 \)を使って表される確率分布の事です。式で書けば、以下のようになります。
$$\begin{eqnarray}
p(x) = \sum _{k} \pi _k \mathcal{N} \left( x| \mu _k , \Sigma _k \right)
\end{eqnarray}$$
適当に混合正規分布のグラフを描いてみます。
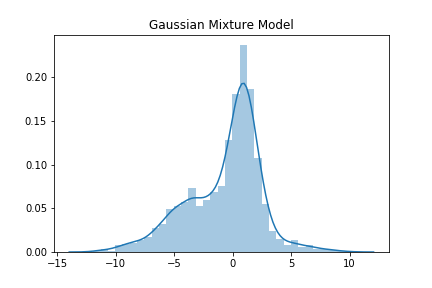
良く見る感じのデータの形をしています。実はこれは、3つの正規分布を合成したものです。このような形のデータを上手く説明してくれるのが混合正規分布です。
EMアルゴリズムの準備
混合正規分布のパラメーターを決定する問題を考えます。一般的には、EMアルゴリズムという手法でパラメーターを推定できます。
混合正規分布は、正規分布の混合割合1 \(\pi _k \)、それぞれの平均値\( \mu _k \) と分散行列\( \Sigma _k \)を決定しなくてはいけません。
正規分布の数は\(K \)個と分かっている2とします。
モデルは以下3です。
$$\begin{eqnarray}
p(x) = \sum _{k} \pi _k \mathcal{N} \left( x| \mu _k , \Sigma _k \right)
\end{eqnarray}$$
データを取得すると、その値が入っているクラスター\( l \) が分かります。\( \pi _k \) がある確率変数 \( z =\{ z_1 , \cdots , z_K \} \) でコントロールされていると考えましょう。\(z_k \in \{ 0,1 \} \)です。
\(z \)に対しては、次のような確率分布4を考えます。
$$\begin{eqnarray}
p(z|\pi ) = \prod \pi _k ^{z_k}
\end{eqnarray}$$
例えば、\( p(z_k =1 ) = \pi _k \) であり、この情報を持っている時は、データのクラスターを知っているので、
$$\begin{eqnarray}
p(x|z_k =1 ) = \mathcal{N} \left( x| \mu _k , \Sigma _k \right)
\end{eqnarray}$$
となります。\(z_1 , \cdots , z_K \)は独立と考えて、
$$\begin{eqnarray}
p(x|z) =\prod_{k} \mathcal{N} \left( x| \mu _k , \Sigma _k \right) ^{z_k}
\end{eqnarray}$$
となります。新しく確率変数\(z\)を導入しましたが、\( z \)を消去した時に最初に設定したモデルが出てこなくては困ります。上手くいくように設定したのですが、一応確かめましょう。
$$\begin{eqnarray}
p(x) &=& \sum_{z} p(x, z)= \sum_{z} p(x|z)p(z) \\
&=&\sum_k \pi_k \mathcal{N} \left( x| \mu _k , \Sigma _k \right)
\end{eqnarray}$$
この変数\( z \)も使って\( \pi , \mu , \Sigma \)を推定しましょう。対数尤度を最大化するパラメーターを推定値とします。
Eステップ
対数尤度を最大化するための準備をします。
\( z_k \)の事後分布を求めます。つまり、データ\( x \)が与えられたときに、そのデータがクラスター\( k \) に属する確率です。ベイズの定理を使って以下のように求められます。
$$\begin{eqnarray}
p(z_{k}=1 |x) &=& \frac{p(x|z_k =1)p(z_k = 1 )}{p(x)}\\
&=& \frac{ \pi_k \mathcal{N} \left( x| \mu _k , \Sigma _k \right) }{ \sum_j \pi_j \mathcal{N} \left( x| \mu _j , \Sigma _j \right) }
\end{eqnarray}$$
この式は後で出てくるので、\( \gamma(z_k ) = p(z_{k}=1 |x) \)と置いておきます。データが大量に ( \(N\)個 )ある時、以下のように確率分布と、変数を用意しておきます。
$$\begin{eqnarray}
p(X| \pi , \mu ,\Sigma) &=& \prod_{n} ^{N} \sum_k p(x_n| \pi _k, \mu _k,\Sigma _k)\\
\gamma(z_{nk}) &=&
\frac{ \pi_k \mathcal{N} \left( x_n| \mu _k , \Sigma _k \right) }{ \sum_j \pi_j \mathcal{N} \left( x_n| \mu _j , \Sigma _j \right) } \\
N_k &=& \sum_n \gamma (z_{nk} )
\end{eqnarray}$$
Mステップ
パラメーターでの微分を求め、 対数尤度を最大化します。対数尤度は以下のようになります。
$$\begin{eqnarray}
L&=& \log p(X| \pi , \mu ,\Sigma) \\
&=& \sum_n \log \sum_k \pi _k \mathcal{N} \left( x_n | \mu _k , \Sigma _k \right)
\end{eqnarray}$$
これを最大にする\( \pi _k , \mu _k , \Sigma _k \)を求めます。\( \mu _k , \Sigma _k \)については、微分するだけ 5 です。\( \pi _k \) については、ラグランジュの未定乗数法で最適な値を求めます。
初めに、 \( \mu _k , \Sigma _k \) で微分しましょう。 計算は頑張って追ってみてください。行列での微分は、先ほど挙げた参考の記事に載っているものを使えばできます。
$$\begin{eqnarray}
\frac{\partial L}{\partial \mu _k }&=&
-\sum_n \gamma (z_{nk} ) (x_n -\mu_k ) \\
\frac{\partial L}{\partial \Sigma _k }&=&
\frac{1}{2} \sum_n \gamma (z_{nk}) \left( \Sigma _k ^{-1} (x_n -\mu_k ) (x_n – \mu _k ) ^{T} \Sigma _k ^{-1} – \Sigma _k ^{-1} \right)
\end{eqnarray}$$
これから、 \( \mu _k , \Sigma _k \) は以下のようになります。
$$\begin{eqnarray}
\mu _k &=& \frac{ \sum_{n} \gamma (z_{nk}) x_n }{N_k} \\
\Sigma _k &=&
\frac{1}{N_k} \sum_n \gamma (z_{nk} ) (x_n -\mu_k ) (x_n – \mu _k ) ^{T}
\end{eqnarray}$$
次に、\( \pi _k \)を決めましょう。ラグランジアンは以下のようになります。
$$\begin{eqnarray}
\mathcal{L} =L – \lambda (\sum \pi _k – 1 )
\end{eqnarray}$$
\( \frac{ \partial \mathcal{L} }{\partial \pi _k } = 0 \)とすることで、以下を得ます。ただし、\(N= \sum_k N_k \)です。
$$\begin{eqnarray}
\pi_ k = \frac{N_k } {N}
\end{eqnarray}$$
これで決定したいパラメータが全て求まりましたが、 \( \gamma(z_{nk} ) \)は \( \pi _k , \mu _k , \Sigma _k \) と複雑な関係にあるので、完全な解にはなっていません。
しかし、パラメーターを1度適当に決めて、\( \gamma(z_{nk} ) \)を計算しておけば、適当なパラメーターの更新値として、 \( \pi _k , \mu _k , \Sigma _k \) が求まります。更新を繰り返して、\(L_{\rm new } – L_{ \rm old } \)が収束したら、更新をやめる事6 でパラメーターの推定が出来ます。
実用上の注意
実務では、データに外れ値が混ざっているのが常です。EMアルゴリズムにかける前に、データをクラスタ分けしてクラスタ数\( K \geq 2\)を決定しなくてはなりません。この時、外れ値があると平均値があるデータ\( x_j \)に一致するようなクラスタ(正規分布) が生成されてしまいます。これが起こると大変なことになります。
そのようなクラスタをの正規分布は
$$\begin{eqnarray}
\mathcal{N} \left( x_j |x_j , \sigma ^2 \right) = \frac{1}{ (2\pi ) ^{1/2} } \frac{1}{\sigma }
\end{eqnarray}$$
となります、外れ値が群生していると、\( \sigma \sim 0 \)です。このとき、分布は非常に尖ったものになり、尤度を取ると発散してしまいます。尤度が非常に大きくなるので、パラメーターの推定が終わらなかったり、無意味なパラメーターになったりします。
データの前処理と、クラスタ分けを丁寧に行っておく必要があります。
まとめ
- データの出所が複数ある時は、一個の確率分布では近似できないことがある
- モデルを混ぜる時、混ぜる比率と確率分布のパラメーターを推定する方法がある
- 適当なパラメーターから初めて、何度か更新することで最適なパラメーターにたどり着くことが出来る。

