
エントロピーの定義から始めて、KLダイバージェンスの意味を理解するのが目標です。
エントロピーがデータの分布の違いを見分けるのに役立つことを説明し、KLダイバージェンスが確率分布同士の距離を測る道具になっていることを解説します。
最後に応用について少しだけ説明します。応用についての詳しい解説は別の記事を読んでください。
参考書として、以下の2冊を挙げておきます。


エントロピーと分布の形
まずはエントロピーの定義を確認します。
\(p\)を(離散)確率分布とします。以下の量\( H\)をエントロピーと呼びます。
$$\begin{eqnarray}
H( p)=-\sum p_i \log p_i
\end{eqnarray}$$
\(p\)が連続の場合1は、以下のようにします。
$$\begin{eqnarray}
H( p)=-\int p(x) \log p(x) dx
\end{eqnarray}$$
また、2つの確率分布\( p(x) , q(x) \)があるとき、\(p\)による\(q\) のエントロピー\(H_p (q) \)を \( \log q(x) \)の\(p (x) \)の期待値で定義します。
$$\begin{eqnarray}
H_p( q)=-\int p(x) \log q(x) dx
\end{eqnarray}$$
この定義だけでは、エントロピーが何を表す量なのか分かりません。エントロピーは以下の性質を持つことが知られています。
[エントロピーの持つ性質]
\(p=\{ p_i \} \)を離散な確率分布とします。つまり、\( \sum^{N} p_i =1 \)とします。
- \( H( p) \geq 0 \)
- もしも、\( p_i =1 \)となる\(i \)があると、\( H=0 \)
- \( H\) が最大になるのは、\( p_ i =1/N \)のとき。
2番の性質から、データのヒストグラムが尖った形な程エントロピーは小さな値を取る事が分かります。逆に、均質的でなだらかなヒストグラムに対しては大きな値を取ります。
性質の証明
性質を確かめてみます。前半2つは簡単です。
\(0 \leq p_i \leq 1 \)なので\( \log p_i \leq 0\)です。これから、エントロピーが0以上であることが分かります。 \(p_i =1 \) という事は、\( \log p_i =0 \)という事です。このとき、他の\(p_i \)は \(0\)となります。従って、\(H(p) = 0\)です。これで性質1,2が分かります。
最後の性質を確かめます。
ラグランジュの未定乗数法で、\(H \)の最大値となる条件を求めます。
ラグランジアンは以下です。
$$\begin{eqnarray}
L = H-\lambda(\sum p_i -1)
\end{eqnarray}$$
\( p_i \) での微分は以下のように計算出来ます。
$$\begin{eqnarray}
\frac{ \partial L} {\partial p_i } = -\log p_i – 1 + \lambda
\end{eqnarray}$$
上の式を0とすると、
$$\begin{eqnarray}
\log p_i = \lambda +1 = 定数
\end{eqnarray}$$
となります。\( p \)が確率分布になるためには全てのiについて \(p_i =1/N \)となるしかありません。
これで3つ目の性質が分かりました。
エントロピーでデータの変化を捉える
実際のデータを使って、エントロピーを計算してみます。 西暦毎に 都道府県別の人口を記録したデータを使います。昔と比べて、都市に人が集中していってるので、エントロピーが小さくなっていくはずです。データはe-Stat に置いてある人口推計を使いました。年代別でグラフを描くと以下のようになっています。
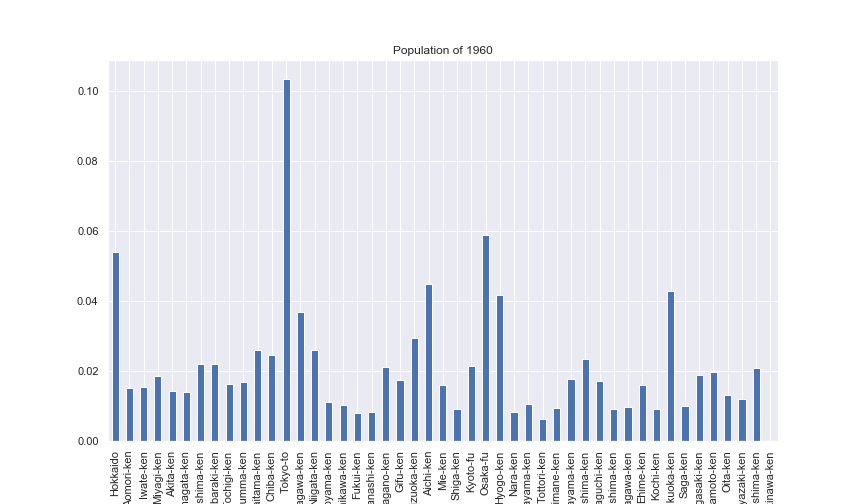

都市部だけ、人口比率が大きくなっていることが分かります。適当な年代でエントロピーを計算させてみます。
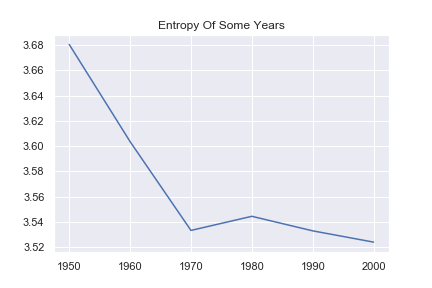
エントロピーが順調に減少しています。人口の分布がある場所に集中し、尖った分布に遷移している事を表しています。これは、都市部に人が集中しているという事実と合致しています。
上で挙げた例のように、エントロピーを計算することで確率分布やデータがどのように変化しているのかを捉える事が出来ます。
基本的な確率分布に対して、エントロピーを計算した記事があるので、興味がある方はどうぞ。

KLダイバージェンス
エントロピーが、一つの確率分布の変化を捉えられることが分かりました。
二つの確率分布 \(p(x) , q(x) \) がある時、エントロピー\( H_q (p) \)を考える事が出来ました。
この量は、\(q \)を基準とした\( p\)のエントロピーと解釈できます。エントロピー\(H_q (q ) \)の最小値は0でしたが、 \( H_q (p) \) の最小値は\( H_q (q) \)です。
\( H_q (p) \) は、\( p \)が\(q \)にどれだけ似ているのかの基準になります。
これを踏まえて、以下の量をKLダイバージェンス(Kullback-Leibler divergence)と呼びます。
$$\begin{eqnarray}
KL(q\| p) &=& H_q (p)- H_q (q) \\
&=&-\int q(x) \log \frac{p(x)}{q(x)} dx
\end{eqnarray}$$
KLダイバージェンスは距離と似た性質を持っています。
[KLダイバージェンスの性質]
\(p(x) , q(x) , q_1(x) , q_2(x) \) を確率分布とします
- \( KL(q \| p) \geq 0 \)
- \( KL(q\| p) =0 \)となるのは、 \( q=p\) となる場合のみ
- \( KL(q_1 \| p) + KL(q_2 \| p) \geq KL(q_1 + q_2 \| p) \)
距離っぽい性質を持っているのですが、\( KL(q \| p ) \neq KL(p \| q) \)なので、数学的には距離とは呼びません。しかし、\(KL( q \| \cdot ) \) という\(p \)についての関数だと考えれば、任意の確率分布と\( q \)との距離を測る事が出来ます。
性質の証明
上に挙げた性質を示すにはイエンセンの不等式( Jensen’s inequality ) を使います。詳しい説明はしませんが、以下の関係式を使います。
$$\begin{eqnarray}
\int \log (f(x)) p(x) dx \geq \log \left( \int f(x) p(x)dx \right)
\end{eqnarray}$$
この関係を認めて、上に挙げた3つの性質を証明しましょう。
$$\begin{eqnarray}
KL(q \| p) &=& -\int q(x) \log \frac{p(x)}{q(x)} dx \\
& \geq & \log \left( \int p(x) dx \right) \\
&\geq & 0
\end{eqnarray}$$
これで1つ目は証明出来ました。2つ目は\( \log \)が良い関数なので成り立ちます。3つ目を考えます。
$$\begin{eqnarray}
&\ &KL(q_1 \| p) + KL(q_2 \| p) – KL(q_1 +q_2 \| p) \\
&=& \int q_1 (x) \log \left( 1+ \frac{q_2(x)}{q_1(x)} \right) + q_2 (x) \log \left( \frac{q_1 (x)}{q_2(x)} +1 \right) dx \\
& \geq & 2 \log 2 \\
&\geq & 0
\end{eqnarray}$$
1行目から2行目への計算は少し端折ってますが、積分の\( \log p(x) \)に関する部分は消える事が分かるので、\(q_1 , q_2 \)に関してまとめると2行目の結果が出ます。次にイエンセンの不等式を使う事で \(2 \log 2 \)が出ます。
正規分布同士のKLダイバージェンス
次に、KLダイバージェンスが、確率分布同士の距離を測っていることを確かめてみます。
具体的には、標準正規分布\( p = \mathcal{N}(x| 0,1 ) \)と、平均値が違う確率分布 \(q= \mathcal{N}(x| \mu ,1 ) \) を用意し、\( \mu \)を変化させたときの\( KL(q| p ) \)を計算してみます。2
gist にも載ってますが、与えたデータは、平均値を変えた正規分布です。それらと、標準正規分布のKLダイバージェンスを計算します。
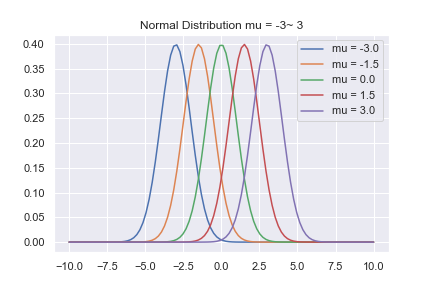
scipy のentropy ライブラリを使うと、KLダイバージェンスを計算出来ます。にentropy(q,p ) のように、サンプルしたデータを与えるだけです。3
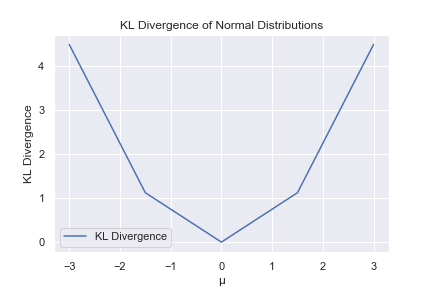
平均値の値\( \mu \)が 0と一致している時のみKLダイバージェンスが0になり、0から離れると大きくなっていく様子が分かります。
確率分布のパラメーターを動かしながらKLダイバージェンスを監視する事で、確率分布が目的の確率分布に近付いているかどうか調べる事が出来るのです。
KLダイバージェンスの応用
KLダイバージェンスは、得られたデータを確率分布で近似するときによく使われます。
最も有名な例が、EMアルゴリズムです。
大まかな議論は以下のようなものです。
元のデータが確率分布\(p(x|\theta ) \)に従うと仮定します。また、 元のデータが陽には見えていない構造を持つと考えます。それを司る確率変数\(Z\) が従う確率分布を\(q(Z) \)と置きます。
対数尤度 \(\log p(x|\theta ) \) が\( KL (p|q ) \)を使って分解できることが計算から分かります。
$$\begin{eqnarray}
\log p(X| \theta ) &=& \mathcal{L}(q, \theta) +KL(q \| p)
\end{eqnarray} $$
KLダイバージェンスを0にして、対数尤度を最大化しよう、という流れで最適なパラメーター\( \theta , Z \)を推定するのがEMアルゴリズムです。詳しい話は解説記事をどうぞ。KLダイバージェンスが大事な役割を果たすアルゴリズムです。
https://masamunetogetoge.com/em-algorithm
https://masamunetogetoge.com/em-algorithm-python
https://masamunetogetoge.com/general-em-algorithm
まとめ
- エントロピーは\( \log \)の期待値
- エントロピーを比べる事で、分布の変化を捉える事が出来る。
- KLダイバージェンスで確率分布同士の距離を測れる
- 確率分布の近似を考えたいときにKLダイバージェンスが使われる

